













































































































 免费参与·100+跨境活动
免费参与·100+跨境活动 
 免费下载·4000+跨境资料
免费下载·4000+跨境资料 
 免费学习·2000+直播课程
免费学习·2000+直播课程 
 免费加入·15万+卖家交流群
免费加入·15万+卖家交流群 


2022-08-16 17:41
 图片来源:图虫创意
图片来源:图虫创意
前言
Cookies的重要性
数据采集的变化&限制
无Cookies的数据分析状态
①营销归因模型(Marketing Attribution Models)
What:什么是营销归因模型?
Why:为什么我们需要营销归因模型?
How:如何建立营销归因模型?
有哪些不同类型的归因模型?
常见的营销归因模型有哪些?
1.首次交互或首次点击模型(First Interaction or First Click Model)
2.最后互动或最后点击模型(Last Interaction or Last Click Model)
3.最后非直接点击模型(Last Non-Direct Click Model)
4.线性模型(Linear Model)
5.时间衰减模型(以及其他考虑时间的模型)(Time Decay Model (and other models that take time into account))
6.基于位置或U形模型(Position-Based or U-Shaped model)
Google工具体系的DDA(数据驱动分析 Data-Driven Attribution)
1.Google Ads的DDA
2.Google Analytics 360的DDA
3.Search Ads 360的DDA
②算法归因模型(Algorithmic Attribution Models)
1. 夏普利值归因(Shapley Value Attribution)——触点价值
1)计算Facebook Ad触点的价值
2)计算Direct触点的价值
2.马尔可夫链归因(Markov Chain Attribution)——链条价值
1)根据视图进行表格分配
2)根据轨迹图具象化数据价值
3)触点价值计算
3.BI/ML归因模型
1)洞察广告渠道运作效果
2)比对不同用户群的获取渠道
3)BI/Business Intelligence 商业智能
结语
前言
我们在数字化独立站演进历程(二)2022年全触点管理&私域营销解读过大型广告平台(Google、Facebook)的商业利益,源于广告平台算法对用户数据的利用。
然而随着隐私政策和Web3.0到来,Cookies(无论第一方Cookies还是第三方Cookies)的生命周期缩短从而导致广告系统收集用户级数据的能力减弱,数字化广告效果展现前所未有的低靡。

(图片来源:甲子光年)
2023年,海外电商营销人员将彻底无法收集目前有关广告渠道有效性的大部分数据——意味着如果还是坚持目前广告投放的管理方式,所有广告(哪怕Google Ads)的ROAS都会异常难看。
而因为广告数据不精准,独立站投放团队目前已经浪费21%的预算——而随着更多Cookies限制以及Google隐私沙盒的采用,这个比例只会更让每个广告主心头滴血。
所有独立站营销团队,在2022年都会面临一个挑战
“如何过渡到一种新的归因分析公式(Attribution Analytical Formula)”
更好地为全球电商营销无Cookies后的变化做好准备
Cookies的重要性
探讨无Cookies时代,当然先要解读Cookies的重要性
举个栗子:
假设我们是要办理银行业务的个人,那么Cookies就是银行给予我们的一次性One-ID
什么是One ID?
这是数字化时代营销的术语,基于每个个人都存在手机号、邮箱、设备ID等不同的ID信息,因此为了更有效识别到个人,结合业务规则、机器学习、图算法等算法,进行ID-Mapping,将各种ID信息都映射到统一ID上。
通过这个统一ID(即One ID),便可关联起各个ID的数据
用户在每个银行首次办理业务,都需要填写相关身份信息——身份证号/手机号码/住宅等,但只需填写一次,不需要在第二次过去的时候再次填写,因为银行已经给了银行卡号作为用户和银行进行交互的One-ID
银行卡:4281261264265622(随手填充的)
姓名:ABC
手机号码:12345678910
住宅:深圳湾一号
PS:One-ID体系在数据指标&分析中有更深层次的应用,银行卡号实际上也不是One ID的最佳选择,此处举例说明只为大家方便理解
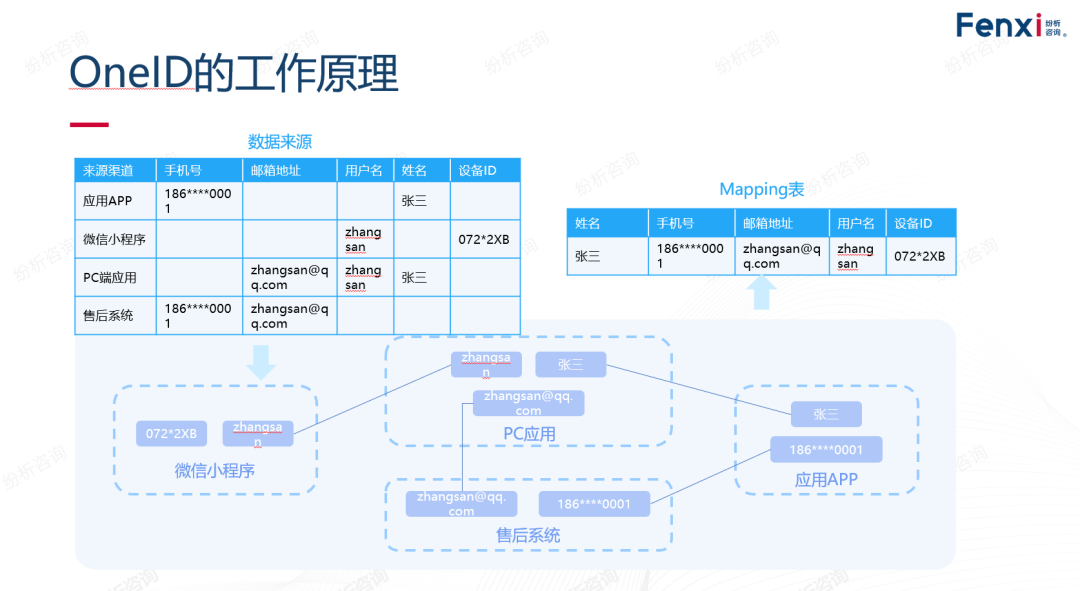
(图片来源:纷析咨询-宋星老师关于One-ID应用的举例说明)
当每个用户第一次访问独立站,Cookie的设置以及推送/保存会经历类似的4个步骤:

(图片来源:Bing)
移动端/PC通过浏览器推送一个请求(Http Request)到服务器
服务器接收请求后,会推送一个响应(Http Response)到客户端
/包含Set-Cookie(响应首部)
移动端/PC在浏览器接收响应并保存Cookie(关键点)
之后向服务器发送请求时,请求(Http Request)
/包含Cookie(用户身份信息/用户行为数据)
本质上,Cookie是一小段代码,当我们用户访问网站时,这一小段代码就会存储在浏览器中,跟踪在该用户网站上进行的种种行为,从中搜集基本数据。
常用Cookie有两种形式:
第一方Cookie,即用户访问我们站点时创建的Cookie——用户通过移动端/PC浏览器停留在我们网页的过程中,浏览器追踪用户的行动中将数据文件保存到用户的移动端或者PC;
第三方Cookie,可以在不同的网站/平台之间共享,广告商和社交媒体可以根据用户近期的停留内容和对内容的行为数据来调整广告策略,定向投放广告——听起来是不是有些耳熟:
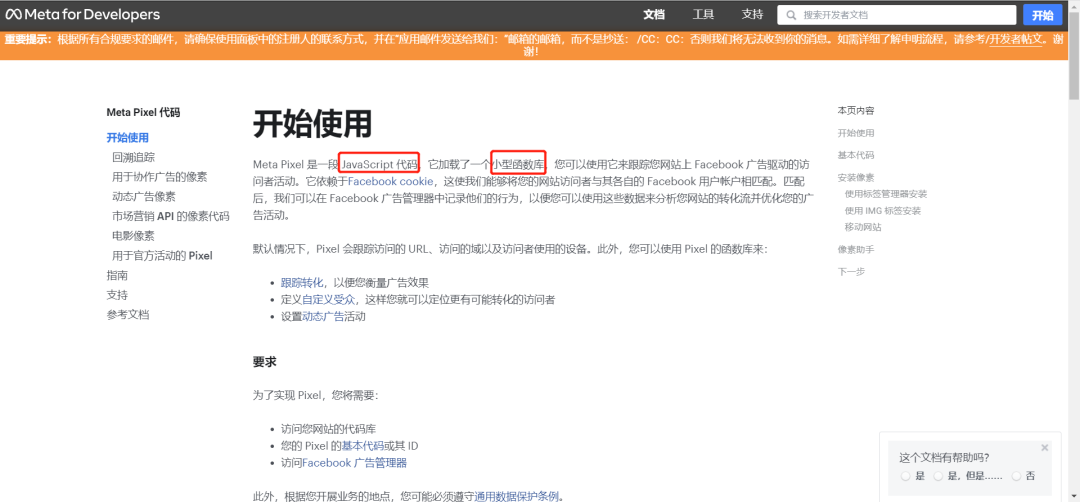
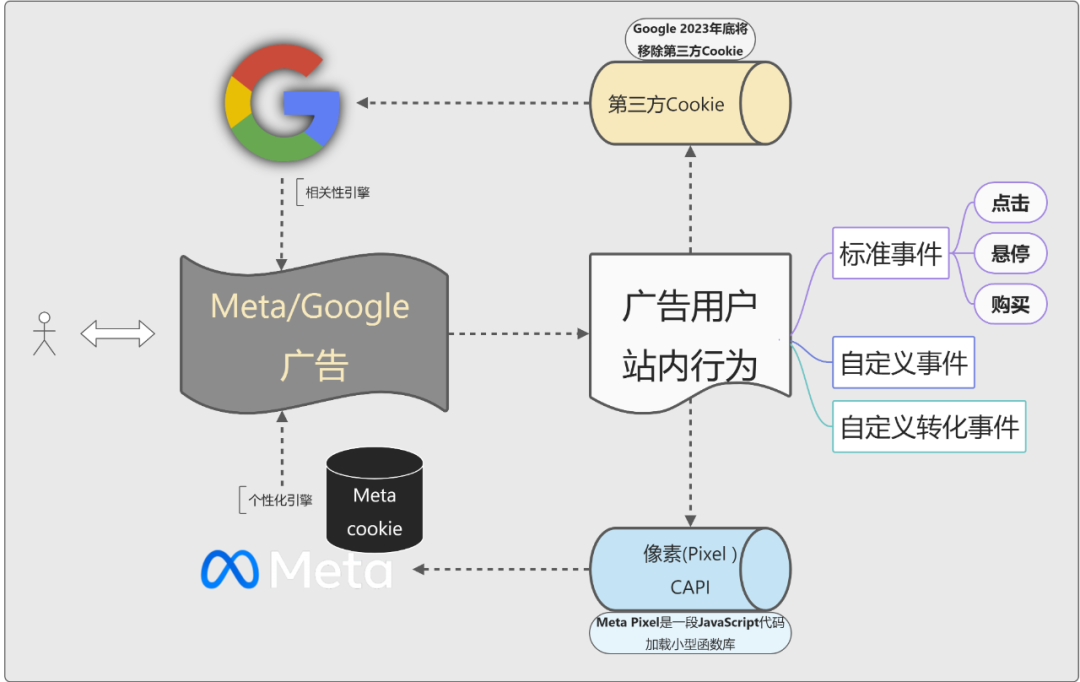
(图片来源:Meta广告后台)
实际上,Meta Pixel就是一段JavaScript代码加载小型函数库,是一个第三方Cookie
所以我们过去依赖的Facebook Ads,本质是用户(①首次广告/②再营销广告)通过浏览器进入站点,以对方的Cookies区别“新”“旧”用户,并且应用数字化广告系统/平台,推送的(再营销)广告

但Cookies和银行卡的区别在于,Cookies是一次性的:
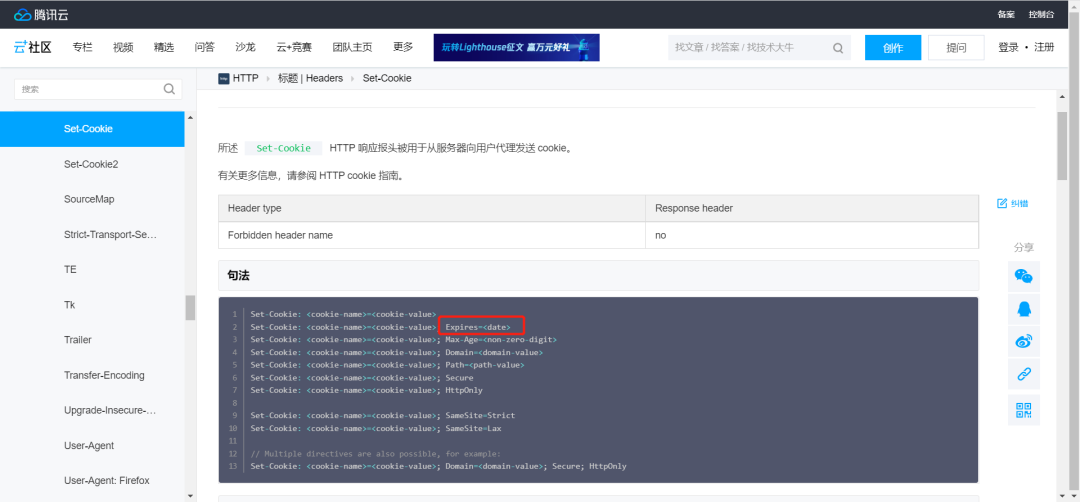
(图片来源:腾讯云)
在Cookies属性值中,Expires= Optional,简单解读一下,这是作为HTTP日期时间戳的Cookie的最大生命周期。
PS:如果未指定,则Cookie将只有会话Cookie的生命周期——会话在客户端关闭时结束,会话Cookie同时被删除。
数据采集的变化&限制
当我们进入无Cookies营销,浏览器已开始限制Cookies的生命周期,甚至完全拒绝使用:
默认情况下,Firefox已经阻止Cookies跟踪
谷歌在2023年底前放弃Chrome浏览器中的第三方Cookies
在Safari中,第三方Cookies的生命周期已缩短为7天,在某些情况下缩短为1天
这意味着第三方网站的重定向可能性将被限制在1天之内
如果用户在1天内没有与网站互动,则Cookies将被删除,并且在下次访问时将识别为新用户
谷歌浏览器在2021年占据超过65.27%的浏览器市场份额,考虑到每月有46.6亿活跃互联网用户,全球使用它的人数估计为30.4亿,跨越超过40 亿台单独设备
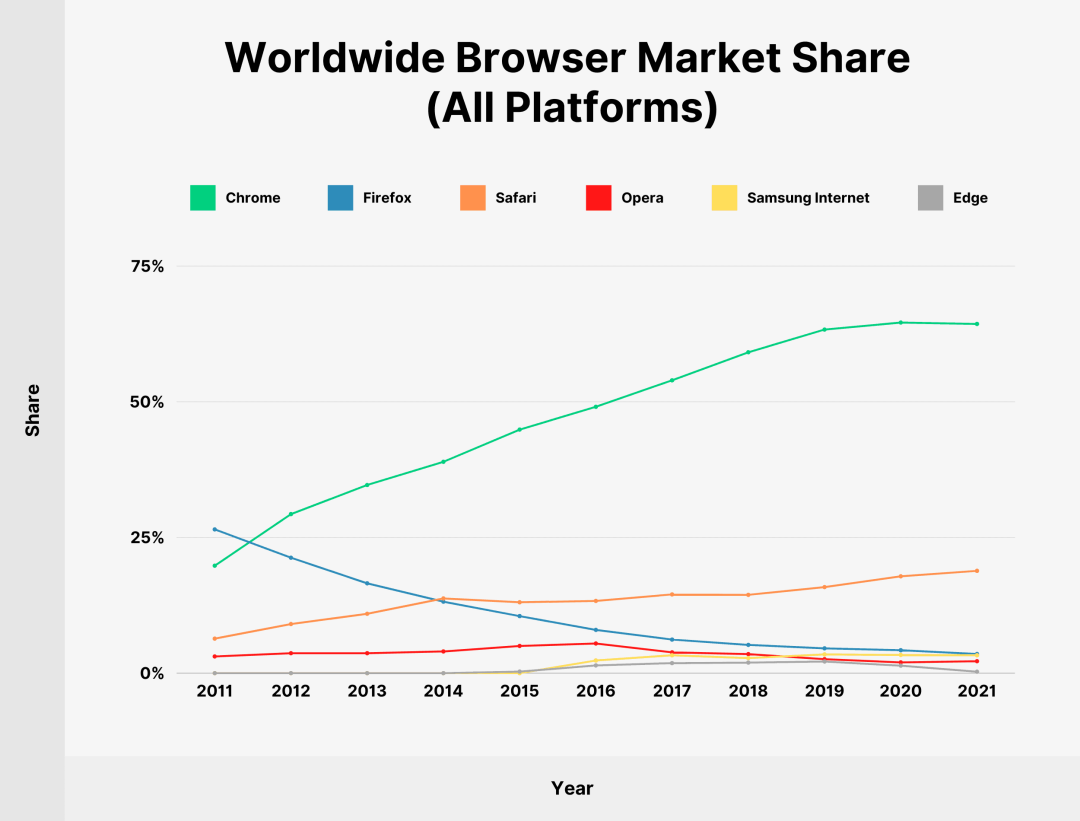
(图片来源:Google Chrome)

图片来源:Jaron Tom以上的变化&限制意味着:
广告服务将限制在用户个人信息级别的跟踪用户活动能力。所有对于个人信息数据是否被收集越加重视,因此广告服务会越加限制追踪用户行为&信息,以保护用户——意味着数据队列分析和审计越加复杂化。
平台和浏览器将限制用户级别的跟踪。例如,iOS已经阻止了IDFA(广告标识符),这是Apple设备用户的Cookies的模拟。默认情况下,移动应用程序追踪IDFA已经是禁止的。没有广告标识符,应用程序发送的用户操作数据不会与特定设备相关联
意味着用户和广告的相关操作,都不会被广告平台/广告主捕抓
(图片来源:Jaron Tom)
这些变化的发生主要有以下三个原因:
数字平权(digital equality)——ATT之后出海互联网广告生态,本身更像一场定价权革命:
对于广告投放者来说,ATT严格来说只是带来的是iOS渠道的整体ROI下降,广告投放者依然可以进行其它的投放驱动。
但从单渠道售卖产品向多渠道甚至全渠道转变,加上营销内容过剩从而导致的消费者对于营销广告的免疫,必然让客户体验在整个消费市场中愈发重要,营销策略也必将从营销渠道为中心转向以用户为中心。
符合用户数据保护要求(GDPR、CCPA)
技术/工具改变——根据Gartner发布的2021年数字商务技术成熟度曲线(Hype Cycle for Digital Commerce),并预测未来两年可视化配置、数字钱包、CIAM(客户身份和访问管理 Customer Identity and Access Management)以及VCA(虚拟客户助理 Virtual Customer Assistant)四项技术的日益主流化将对数字商务产生重大影响
——工具是营销技术的结晶,技术是需求的推导,以客户为中心的需求诞生客户为中心的工具
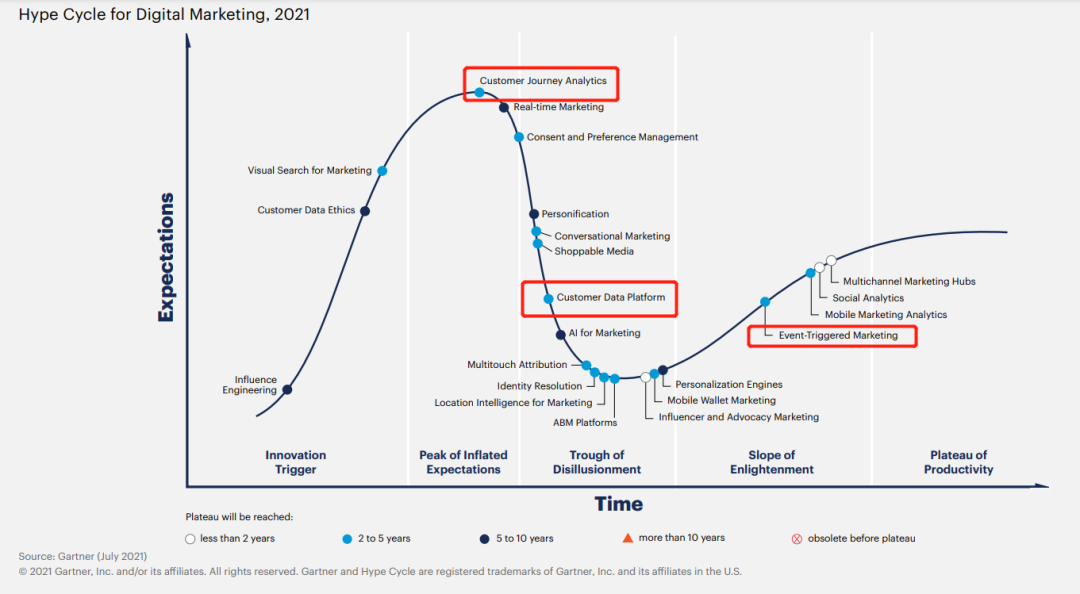
(图片来源:https://www.gartner.com/en/conferences/calendar)
无Cookies的数据分析状态
“新”网站用户的份额将会增加,尽管这些“新”用户中的很多实际上是分配了“新”Cookie的老用户。
直接流量的份额将会增加,因为大多数分析系统会默认使用最后非直接点击归因模型。
如果用户在周一点击广告链接,周二直接返回网站,系统会将第二次会话的来源分配给广告活动,而不是直接客户。
但如果这是一个“新”用户,那么与吸引该用户的广告活动没有任何联系。
转化链的长度会减少。如果之前可以观察到用户在完成转化之前进行了几次点击,那么现在可以与一个用户关联的接触点数量将会减少。
队列报告将受到限制。由于同类群组报告是基于用户属性构建的,因此这些属性(一系列操作、一个订单)将不再可能组合在一起。
归因质量会下降。此前依靠传统和简单的方法(例如“Last Click”),直接将广告系列与来源联系起来。但IDFA被禁之后,广告活动与转化的联系准确性急剧降低。
Facebook和Shopify订单同步不准的原因在这里
尽管如此,卖家的广告营销反而更依赖Last Click,因为只有1个会话或1天内的用户历史记录可供分析系统使用,因此评估将更接近末次互动归因模型(Last Click Attribution Model)
听起来挺矛盾,但这就是目前独立站投放的尴尬——投放越加收窄,而且一扩就崩
多触点关联转化会在评估广告组时将会增加考虑(过往基本只考虑Facebook投流)。包括广告商在内都已经开始通过考虑多触点关联转化来评估多渠道(Multi-channel)乃至全渠道(Omni-channel)营销——因为无法观察用户对广告的反应,意味着单触点的投放基本都属于盲投。
(图片来源:Bing)
①营销归因模型(Marketing Attribution Models)
What:什么是营销归因模型?
这是一个营销学术用语
——营销归因(Attribution)分析是应用统计方法为购物路径的每一个触点分配转化价值,归因模型(Attribution Model)则是一个框架,每种归因模型都会以不同的方式在每个触点上分配转化价值。
(图片来源:Bing)
Why:为什么我们需要营销归因模型?
在复杂的数据爆炸时代,大量的社交媒体&用户数据每天都在指数级别增加;
用户复杂的消费行为路径,反映到广告投放的效果评估上,往往会产生一系列的问题:
哪些营销渠道完成转化销售?
转化率(Conversion rate)分别是多少?
转化价值的背后,是源自于怎样的用户行为路径而产生的?
如何使用归因分析(Attribution Analysis)得到的结论,测试出转化率更高的渠道组合?
大部分卖家第一反应就是:当然是用户点了哪个广告(尤其是Facebook AD,大部分卖家都偏爱Add To Cart)从而进去商品详情页产生购买,当然那就是产生作用的出单广告。
这是最常用的(甚至可以说是,基本都用的)分析方法,最简单粗暴的单渠道归因模型
——这种方法通常将销售转化归功于用户第一个(首次互动模型,First Click Attribution Model)或者最后一个广告触点(末次互动模型,Last Click Attribution Model)的渠道。
然而,这是理想情况下的归因模式
客户会在第一次查看广告后立即购物
(此类情况,是在投放的角度,是素材差异化,也是大部分投手每天都在疲于测试各类广告素材的原因)
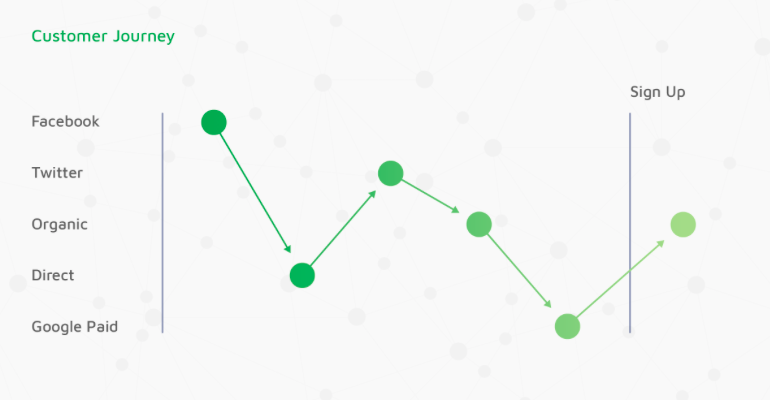
实际上,事情要复杂得多。例如,举一种可能的情况是:
了解——客户看到广告,点击网站链接,并注册身份留下联系方式(邮件),然后分心并关闭网站。
购买思维过程(转换窗口) ——客户选择产品、查看评论并比较商品。同时,过程中会收到我们的营销邮件/推送,并在社交网络(例如Facebook、Instagram和Twitter)上看到广告,并且在YouTube或者TikTok观看我们合作的KOL视频/测评。
购买(转化) ——客户返回网站(转化可以是直接的、通过收藏夹、从广告/KOL渠道或自然搜索)并最终进行购买。
重新购买(客户留存) ——再营销,并通过EDM和社交媒体帖子提醒客户/推送新的产品,低成本召回客户并转发销售。

在用户拥有不止一个触点,尤其每一个广告触点,在当下的流量环境中不具备完整的用户数据反馈,归因分析(Attribution Analysis)帮助我们清晰感知哪个渠道/触点促成了购买,以及它们到底如何影响转化,从而更合理分配广告预算,真正实现增加收入并降低成本。
“我知道在广告上的投资有一半是无用的,但问题是我不知道是哪一半。”
百货业之父约翰·沃纳梅克(John Wanamaker)
How:如何建立营销归因模型?
有哪些不同类型的归因模型?
归因模型有几十种可能的存在,而根据计算中使用的逻辑,它们可以以不同的方式分类。
如果我们在订单之前查看渠道在客户旅程中占据的位置,那么我们使用的是基于位置的归因模型(时间衰减,基于位置)。如果计算考虑到所有数据,而不仅仅是通道在链中的位置,那么它就是一个算法归因模型(数据驱动,马尔可夫链)。
如果我们只将所有价值赋予一个参与渠道的渠道,那么它就是一个单渠道模型(最后点击,第一次点击)。如果价值分布在链中的所有渠道中,那么它是一个多渠道归因模型(线性,时间衰减)。
常见的营销归因模型有哪些?
让我们从最简单的基于位置的营销归因模型开始,这些模型在免费版的Google Analytics中直接使用

Organic原生流量(比如SEO)和Direct(直接流量)区别在于

(图片来源:Google平台截图)
原生流量大部分来源于我们内容营销,直接流量来源于用户的口碑相传——也就是我们强调过的
Earned-Media
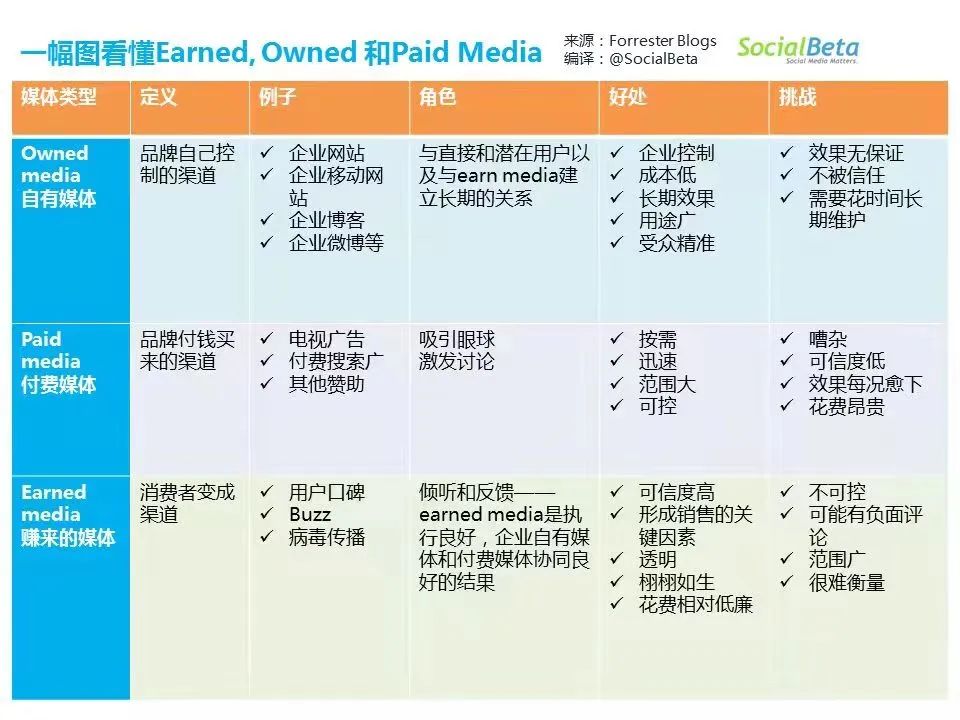
(图片来源:https://socialbeta.com/)
1.首次交互或首次点击模型(First Interaction or First Click Model)
使用这些模型,从转化中获得的所有价值都归因于引导用户进入漏斗的第一个来源。例如,如果我们有一个由四个触点组成的链,如下图所示,根据First Click模型,转化的全部价值将归因于CPC渠道。
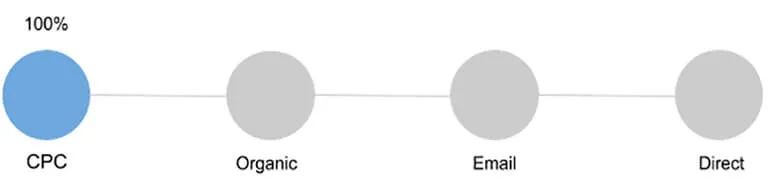
(图片来源:Jaron Tom)
优点:易于设置和使用,因为没有关于渠道之间价值分配的计算或争论。
缺点:没有显示全貌,并且高估了顶部的频道;用户通常在购买前与其他多个接触点进行交互,而首次交互模型完全忽略了这些。
适用于希望提高品牌知名度和受众范围以及了解在哪里购买可以转化的流量的企业。对于专注于需求生成和品牌知名度的营销人员很有用。
2.最后互动或最后点击模型(Last Interaction or Last Click Model)
根据这个模型,转化的全部价值流向了用户在转化之前接触到的最后一个渠道。所有其他渠道的贡献被忽略。在我们的示例中,所有值都将转到Direct通道。
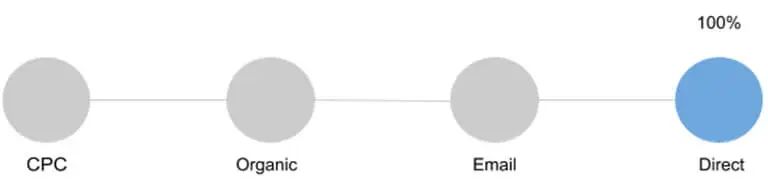
(图片来源:Jaron Tom)
优点:许多营销人员都熟悉的流行模型;非常适合评估快速购买的活动,例如季节性商品。
缺点:与所有单通道模型一样,它在订购前忽略了链中其他来源的作用。
适用于销售周期短、最多只使用三个广告渠道的卖家(比如只在Facebook投放的投流型卖家)。
3.最后非直接点击模型(Last Non-Direct Click Model)
Google Analytics报告中默认使用此模型——整个转化价值分配给链中的最后一个通道,但如果最后一个通道是Direct,则该值将归属于前一个通道。
背后的逻辑是,如果用户通过书签或输入URL找到我们的独立站,表示他们极大可能已经熟悉我们的网站。
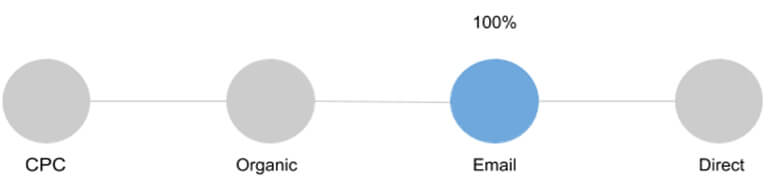
(图片来源:Jaron Tom)
优点:允许忽略在广告成本方面较低的渠道并专注于付费来源。此外,Last Non-Direct Click 可用于与其他归因模型进行比较。
缺点:没有考虑其他渠道的贡献。此外,通常链中倒数第二个来源是电子邮件。我们了解到客户来自某个地方并留下了他们的电子邮件地址。但是使用最后的非直接点击,我们很容易低估帮助客户熟悉品牌、留下电子邮件并最终决定购买的来源。
适用于想要评估特定付费渠道的有效性并且品牌识别不再那么重要的企业。
4.线性模型(Linear Model)
这个基本模型只是简单地将交易价值平均分配给链中的所有来源。
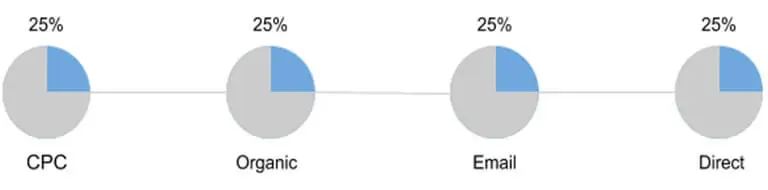
(图片来源:Jaron Tom)
优点:简单,但同时比单渠道归因模型更先进,因为它考虑了转化前的所有会话。
缺点:如果我们需要重新分配预算,则无用;在渠道之间平均分配它不是最好的选择,因为它们不能同样有效——举个例子,KOL渠道和Facebook/Google广告同时在转化出单,但KOL和FacebookAD的不确定性(KOL有效果但难以量化追踪,Facebook广告现状大家懂的都懂)都会让广告部门分配预算时候分外抓头。
适用于销售周期较长的B2B公司等企业,在渠道的各个阶段与客户保持联系非常重要。
5.时间衰减模型(以及其他考虑时间的模型)(Time Decay Model (and other models that take time into account))
使用时间衰减模型,交易的价值在通道之间增量分配。也就是说,链中的第一个来源获得的价值最少,而最后一个且最接近转换的来源获得的价值最高。
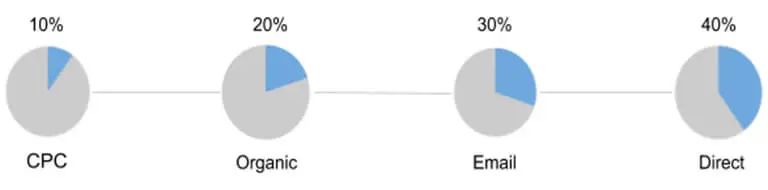
(图片来源:Jaron Tom)
优点:链中的所有渠道都分得一杯羹。最多的功劳归于推动用户购买的渠道。
缺点:导致用户进入漏斗的来源的贡献被大大低估了。
适合那些想要评估时间有限的促销活动的有效性的人。
6.基于位置或U形模型(Position-Based or U-Shaped model)
对于这些模型,大部分功劳归于两个来源(各占 40%):一个向用户种草,一个完成交易。剩下的 20%平均分配给漏斗中间的所有渠道。
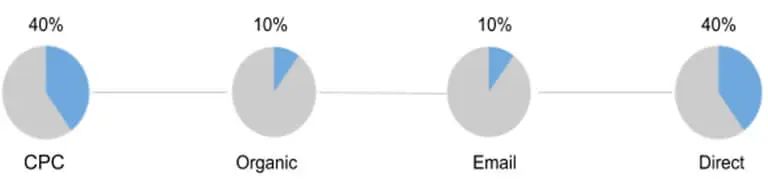
(图片来源:Jaron Tom)
优点:为在大多数情况下发挥最重要作用的渠道赋予最大价值:那些吸引客户并激发转化的渠道。
缺点:有时链路中间的会话比第一眼看起来更能鼓励用户。例如,帮助客户将产品添加到购物车、订阅邮件通讯或点击关注价格。使用基于位置的模型,此类会话及其影响力被低估了。
适用于同样重要的是吸引新观众并将现有访客转化为买家的企业。

图片来源:Jaron Tom消除这些阻碍,解决归因问题会容易得多。
Google Ads、Double Click和其他一些服务也有自己的归因模型,但它们的共同缺点是我们只能使用服务的内部数据进行计算。
不过以Google工具的DDA(数据驱动分析 Data-Driven Attribution)为例,我们可以简单介绍如何从单一归因分析模型转为更复杂的
——以我们的Google Ad帐户数据作为分析的起点,与具有预定义公式的标准模型不同,DDA使用算法对每个案例进行不同的分析,并评估漏斗中渠道的相互影响,即使它是复杂、不一致和多步骤的。
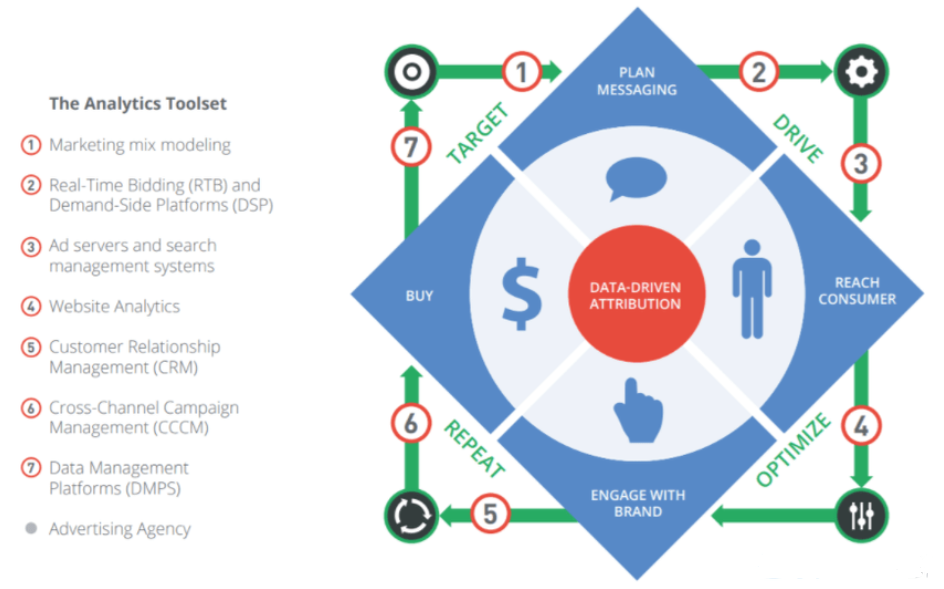
(图片来源:Google Ads)
Google工具体系的DDA(数据驱动分析 Data-Driven Attribution)
1.Google Ads的DDA
Google Ads中的默认归因模型是最终点击,但如果满足最低要求,则可以配置以数据为依据的归因。默认情况下,数据驱动的归因分析Google广告的所有点击,而不是整个客户旅程。根据这些点击,该模型将购买的用户与未购买的用户进行比较,并确定导致转化的广告互动中的模式。要增加转化次数,可以使用根据DDA模型中的信息进行优化的自动出价策略。
与Search Ads 360相比,Google Ads不允许跨多个引擎运行营销活动,并且无法提供太详细报告。
该产品适用于需要优化营销活动和关键词的大中型企业。
关于Google Ads中的DDA,可以观看Google Ads中使用数据驱动归因的官方YouTube视频了解更多。
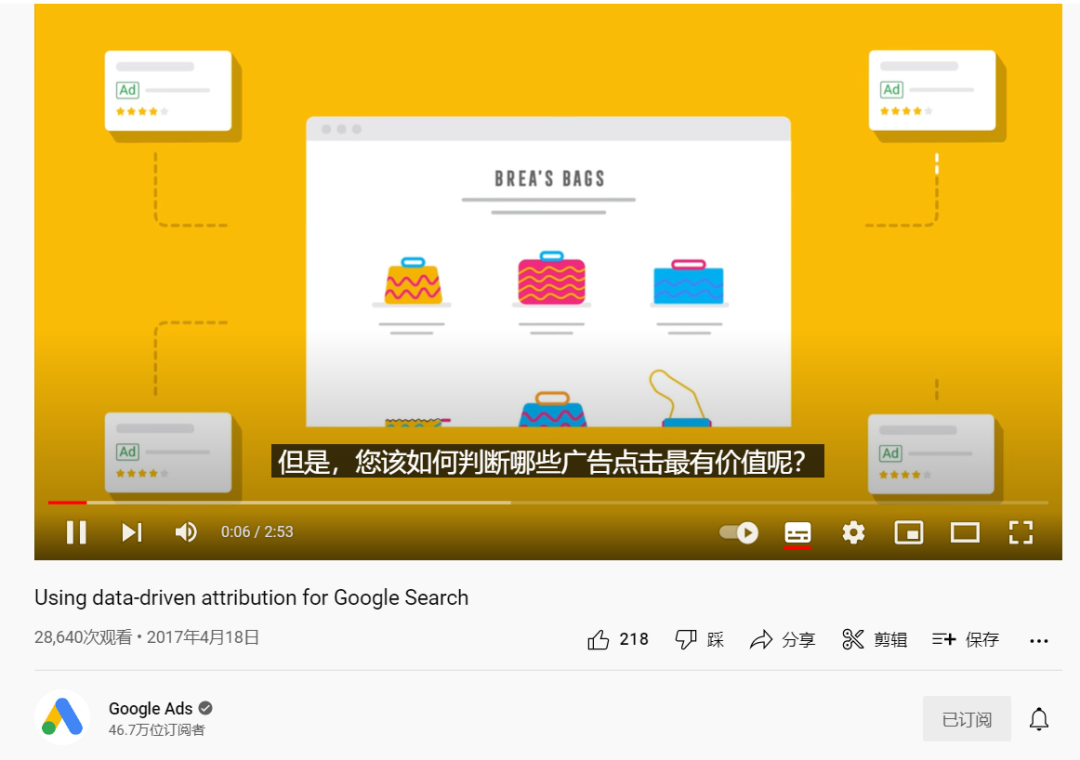
(图片来源:Google Ads)
Google Ads使用DDA的最低要求以及优缺点。
最低要求:
过去30天内在受支持的网络中进行了3,000次广告互动
过去30天内的300次转化
要继续使用此模型,必须在过去30天内达到以下最低转化阈值:
2,000次广告互动
200次转化
Google Ads中DDA模型的优点:
帮助优化关键字和付费广告系列
帮助优化出价
分析哪些广告在实现业务目标方面发挥着最重要的作用
Google Ads中DDA模型的缺点:
无法获得在线用户旅程的全部概览
需要连续30天保持必要的转化次数和点击次数,然后才能在Google Ads中查看数据
如果数据低于所需的最小值,归因模型将自动切换为线性
2.Google Analytics 360的DDA
借助Google Analytics 360,可以使用基于Shapley Value方法(Shapley Value是合作博弈论中的一个解决方案概念,以Lloyd Shapley的名字命名——他于1951年将其引入并于2012年获得诺贝尔经济学奖。我们会在下文算法模型中详细解释)的多渠道漏斗 (MCF)数据驱动归因。该算法通过现有接触点分析用户的路径,然后模拟一个替代变体代替其中一个缺失接触点。
这准确地展示了特定渠道如何影响转化的可能性。以数据为依据的归因评估来自自然搜索、直接流量和付费流量的数据以及我们导入到Google Analytics的所有数据,包括来自其他Google 产品(例如Google Ads、Campaign Manager 360)的数据。
借助Google Analytics 360 中的DDA,我们可以概览渠道中所有用户的在线操作,以及每个渠道如何影响转化。这个选项是最适合大型平台式网站。

(图片来源:Google Ads)
Google Analytics 360使用DDA的最低要求以及优缺点。
最低要求:
过去 30 天内获得15,000次点击和600次转化的Google Ads 帐户
必须设置电子商务跟踪或目标
如果满足这些要求,就可以开始在Google Analytics 360中使用DDA。要继续使用它,同时必须在过去28天内满足以下最低转化阈值:
每种类型的400次转化,路径长度至少为两次互动
特定视图中的10,000条交互路径
Google Analytics 360中DDA的优点:
全面分析客户的在线旅程
查看哪些广告、关键字和广告系列对转化的影响最大——对,就是现在困扰绝大部分卖家的问题,广告订单数据丢失
根据过去的转化数据分配收入功劳
分配给每个接触点的信用量取决于接触点的顺序
数据分析立即开始,我们的第一个模型的报告将在7天内提供
Google Analytics 360中DDA的缺点:
账户成本高:150,000美元/年起
隐藏的计算逻辑:报告中没有解释
需要始终如一的大量点击和转化
不包括离线数据(电话、CRM中的交易)
需要Google Ads帐户
最近很多卖家Google广告账号被挂,让本来只是条件的元素变为缺点,分外唏嘘。
3.Search Ads 360的DDA
由于与Google Marketing Platform的原生集成,Search Ads 360可跨多个搜索引擎(Google Ads、Microsoft Advertising、Yahoo! Japan Sponsored Products、Baidu 和 Yahoo! Gemini)管理广告Campaigns
默认情况下,Search Ads 360使用最终点击归因模型,但如果满足最低点击和转化要求,也可以配置 DDA。与Google Analytics 360和Google Ads不同,Search Ads 360中的数据驱动归因分析Google Marketing Platform的转化跟踪系统Floodlight中的活动。
该归因侧重于付费营销活动,并展示关键字点击如何影响转化,因此还可以调整或创建新的出价策略,该策略将根据模型数据自动优化出价。
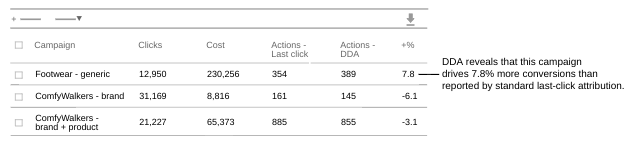
(图片来源:Google Ads)
Search Ads 360服务适用于转化次数较多且需要优化其付费广告系列的网站。
让我们看看在Search Ads 360中使用以数据为依据的归因的最低要求和优缺点。
最低要求:
过去30天内的点击次数为15,000次
过去30天内的600次转化
在 Search Ads 360 中使用DDA的优点:
近乎实时地获取报告数据
智能出价+DDA自动优化出价
最多可创建五个DDA模型来比较不同渠道分组的数据
可以上传离线转化数据(例如CRM中RFM数据)比对分析
考虑跨环境转化
在 Search Ads 360中使用DDA的缺点:
忽略搜索和展示展示次数
可能不完全准确:如果无法衡量所有转化次数,Search Ads 360会使用机器学习和历史数据来模拟转化次数
仅跟踪归因于付费搜索的转化次数
实现所有功能所需的额外设置:Campaign Manager、1组Floodlight活动和Search Ads 360 Natural Search报告
无法分析由Google Ads、Google Analytics或其他转化跟踪系统跟踪的转化
结论
提供数据驱动归因的Google产品允许我们跟踪不同的渠道,确定在Google搜索引擎中我们的在线广告中,存在哪些最有效和最不有效的部分,并详细分析用户的在线旅程。
尽管Google的数据驱动归因通常被视为一种模型,但其实施方式因产品而异。为了有效地测量数据,我们需要选择适合自己的数据类型的服务——以下是Google产品DDA的主要重点:
Google Ads会跟踪Google搜索中的广告点击次数。
Google Analytics 360基于多个渠道及其在渠道中的相互关系跟踪所有用户操作、点击和显示。
Search Ads 360会跟踪Floodlight活动和付费广告系列。
②算法归因模型(Algorithmic Attribution Models)
正常状态下,我们在Google Ads或Facebook(Meta)上设置广告,大部分是通过最后一次点击(Last Click)评估广告Campaign是否有效。
——换言之,在我们的广告管理面板或Google Analytics中,仿佛使用复杂的归因模型是没有意义的。
但是,随着当Apple宣布他们的iOS 14.5更新将允许用户选择退出跟踪cookies时,游戏规则已经全盘改变。因为无法观察最后一次点击(Last Click),也从而导致整体归因效果分析失去效果。
——所有营销/投放都失去了他们的“眼”,直接导致每个独立站的投手不单单需要猜测自己手头上哪个广告Campaign在生效出单,更需要为如何优化广告/增长用户的计划而抓头。
因此在无cookies状态下,评估我们独立站的营销广告状态,需要评估所有广告来源对彼此的影响,并且将来自不同广告服务、Google Analytics,乃至我们的CRM的数据组合到一个系统中,并使用更复杂的归因模型——算法归因模型,其中包括我们接下来介绍的数据驱动驱动(在Google Analytics 360中)、马尔可夫链、BI/ML归因和自定义算法。
——否则,我们将无法了解哪些广告渠道可以结合地协同工作以及我们的用户在我们营销路径的哪些阶段。
1.夏普利值归因(Shapley Value Attribution)——触点价值
付费版Google Analytics的用户可以访问数据驱动的归因模型,上文描述的所有归因模型都使用由网络分析系统or我们自身设置的规则。
相比之下,Shapley Value模型没有任何预定义的规则,它基于数据和Shapley向量计算触点的值。
——改变会话的顺序,Shapley Value模型中的触点Value不会改变
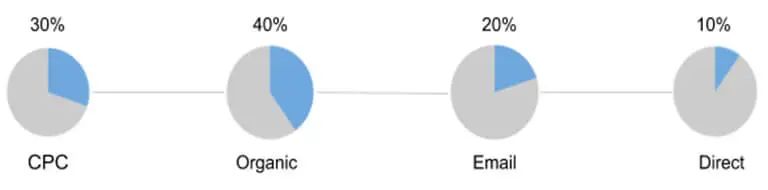
(图片来源:Jaron Tom)
根据维基百科,Shapley Value (属于合作博弈论)是参与者之间价值的最佳分配方案之一,为合作博弈构造一种综合考虑冲突各方要求的折中的效用分配方案,保证分配的公平性从而有效分配所有参与者联合产生的总盈余。
Shapley Value是合作博弈论中的一个解决方案概念(在博弈论中,解决方案概念是预测游戏将如何进行的正式规则。这些预测被称为“解决方案”,描述了参与者将采用哪些策略,因此也描述了游戏的结果。最常用的解决方案概念是均衡概念,最著名的我相信大家都会听过——纳什均衡),通常被认为是博弈论发展最重要的贡献之一。Lloyd Shapley也因此与Alvin E. Roth一起获得了2012年诺贝尔经济学奖——用于稳定配置的理论和市场设计的实践。
要了解数据驱动模型的工作原理,请考虑一个特定示例。假设我们有两条导致交易的链(“全链路”这个词应该是16年从阿里出来的,用于描述用户从接触到转化继而自传播的转换历程):
Facebook Ad → 0美元销售 —— (只是举例,但如果是目前大部分独立站投手的现状🤪)
Facebook Ad → Direct → 500美元销售
Direct → 300美元销售
我们在示例中专门使用了短链,以免使已经很复杂的公式复杂化。
我们需要如何确定每个触点分别带来了多少以及它们一起带来了多少:
V1 (Facebook Adt) = 0$
V2 (Facebook Ad + Direct) = 500$
V3 (Direct) = 300$
触点的Shapley Value使用以下公式计算:
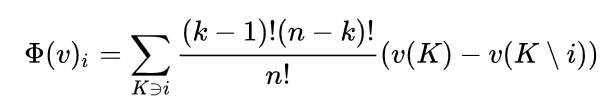
(图片来源:Wiki百科截图)
其中公式中的
n 是玩家的数量(在我们的例子中,指代用户触点)
v 是触点带来的价值
k 是联盟 K 的参与者数量
假设
C1 是 Facebook Ad的触点Value。
C2 是 Direct 的触点Value。
如果我们将示例中的值插入到这个公式中,我们会得到以下结果:
C1 = (1 - 1)!× (2 - 1)!/2!× (0 - 0) + (2 - 1)!× (2 - 2)!/2!× (500$ - 300$) = 0 + 100$ = 100$
C2 = (1 - 1)!× (2 - 1)!/2!× (300) + (2 - 1)!× (2 - 2)!× (500$) = 150$ + 250$ = 400$
现在,我们将为那些被公式吓到的人用简单的语言来解释这一点😀
1)计算Facebook Ad触点的价值
Facebook Ad本身并没有给我们带来任何东西,所以我们将拥有的第一个元素是0$。
Facebook Ad和Direct一起带来了500美元,仅Direct就带来了 300 美元。我们从触点组合带来的金额中减去Direct赚到的钱,然后将结果除以2:(500$ - 300$) / 2 = 100$。这是我们的第二个元素。
现在加上0$ + 100$ = 100$——Facebook Ad在我们此次触点组合中的价值。
2)计算Direct触点的价值
Direct完成300$,将其除以2,获得150$。
Facebook Ad + Direct组合带来了500美元,除以2得到250$。
我们将这些数字相加,得到400$作为Direct触点的价值。

图片来源:Jaron Tom
2.马尔可夫链归因(Markov Chain Attribution)——链条价值
马尔可夫链(Markov Chain, MC)是具有有限数量结果的随机事件序列,其特点是在固定现在的情况下,未来独立于过去。
最初,气象员、博彩公司和其他人使用马尔可夫链来解决预测问题。随着数字市场的发展,人们最近开始使用它们来评估广告活动。
基于马尔可夫链的归因有助于回答多个关联广告触点将如何影响转化的问题。
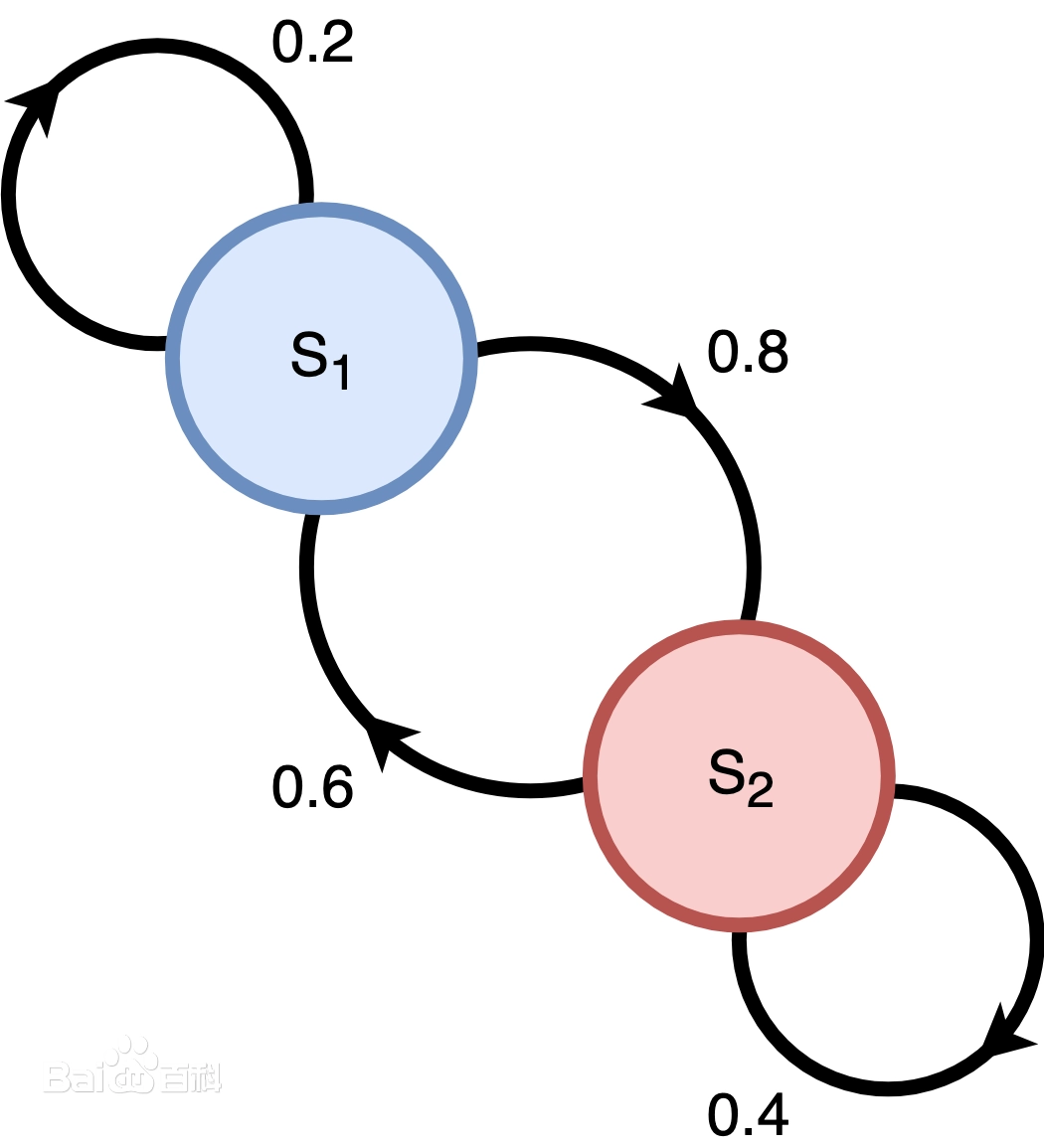
(图片来源:Wiki百科截图)
要了解马尔可夫链的工作原理,我们以自身独立站转化过程最常用的链路作为具体示例。
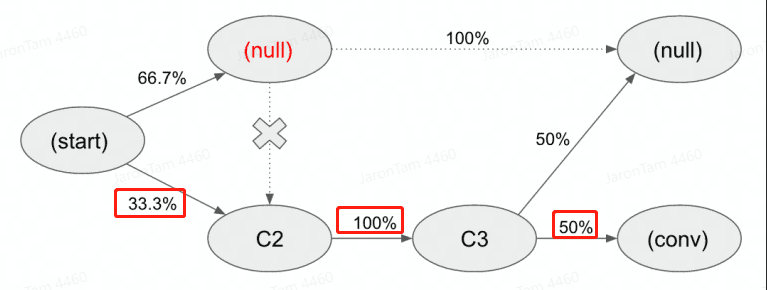
假设我们在3个广告触点(C1:Facebook Ad /C2:Google CPC广告/C3:EDM)组成的广告关联组合中,并试验出如下3条链路:
Start → C1 → C2 → C3 → 转化成功(Сonversion)
Start → C1 → 转化失败(null)
Start → C2 → C3 → 转化失败(null)

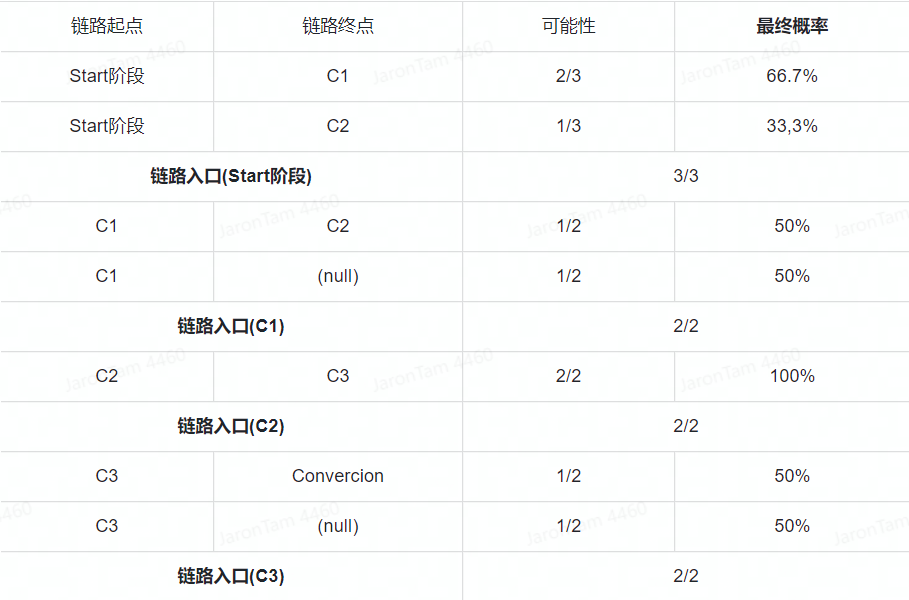
图片来源:Jaron Tom1)根据视图进行表格分配

第一列展示我们的客户路径——在我们的示例中是2个链路。
第二列展示路径在模型内部的视图,包括链路入口(Start阶段)和链路出口(Conversion或Null)。
第三列展示触点分对,因为我们需要评估从一个触点到下一个触点的所有可能转化路径。
然后我们需要计算每个可能的转化选项的概率并将它们放在一个单独的表中
概率来源于分析有关用户操作的真实数据
通过Google Analytics完成数据采集
2)根据轨迹图具象化数据价值
为了保证本篇推文的完读率,我们在轨迹图上展示以上表格中所有数据表达的意思:
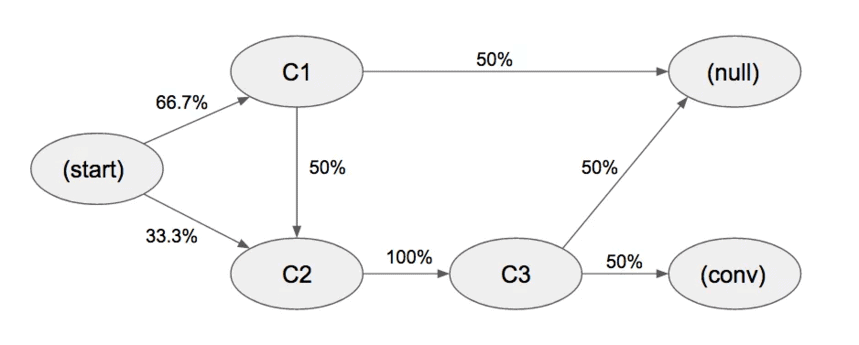
(图片来源:Jaron Tom)
在轨迹图中,我们可以看到了数据采集表中已采集的转化选项&转化概率。
一切都从(Start阶段)开始:
三分之一的用户进入频道C2触点,三分之二的用户进入C1触点
此外,C1触点的一半用户离开漏斗,另一半进入C2触点,然后到C3触点
最后,剩余用户中有50%进行了购买
请注意,在我们的示例中,实际上只存在两个转化路径,并且都通过C2触点
3)触点价值计算
再次为了挽救完读率,又或者说,我们要解释到底为何要做这么复杂的运算?
本质上,这是是一个否定推演,也就是说依次删除每个触点,观察它的缺失将如何影响转化(Convercion):
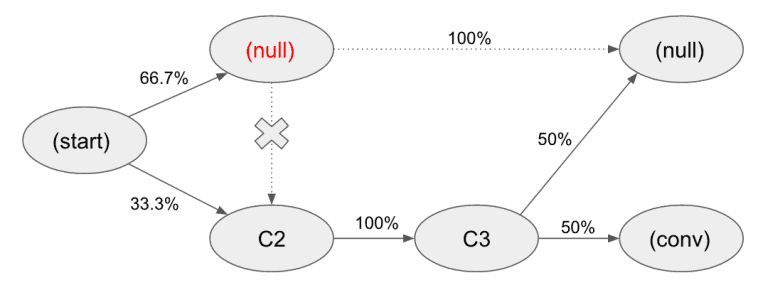
(图片来源:Jaron Tom)
例如,如果我们从举例中删除C1触点,我们会失去50%的转化——我们是怎么得出这个结论的?
在马尔可夫链中,触点价值计算分三个阶段进行:
1.计算每个触点的转化概率
更准确地说,需要弄清楚如果从链路中删除单一触点后,我们会获得多少转化。
每个触点的转化概率 (P) 使用以下公式计算得出:
P1 = (33.3% × 100% × 50%) = 16.7%
P2 = (33.3% × 0 × 50%) = 0
P3 = (33.3% × 100% × 0) = 0
让我们仔细看看第一个公式,如何计算出C1触点的转化概率。
当我们从模型中删除C1触点,并将所有剩余的从导致购买的链中转移的概率相乘。
(图片来源:Jaron Tom)
也就是说,我们将33.3%乘以100%乘以50%。结果,我们得到16.7%
——如果我们从链路中移除C1触点,这是我们将获得的转化百分比。
如果我们删除触点C2和C3,那么我们将根本没有转化。
2.确定每个触点的删除效果(R)
这里计算的是,如果我们从漏斗中删除触点,我们将失去的转化百分比,其计算方式如下:
减去转化单位 (P) 除以链路入口的用户数量(转化概率),从100%开始:
R1 = 100% - (16.7% / 33.3%) = 50%
R2 = 100% - 0 = 100%
R3 = 100% - 0 = 100%
3. 最后,我们计算每个触点的Value(V)
——丢失转换的百分比 (R) 并将其除以所有系数(R1、R2 和 R3)的总和。
V1 = 50% / (50% + 100% + 100% ) = 20%
V2 = 100% / (50% + 100% + 100% ) = 40%
V3 = 100% / (50% + 100% + 100% ) = 40%
C1:Facebook Ad /C2:Google CPC广告/C3:EDM

优点:基于马尔可夫链的归因模型允许我们评估触点对转化的相互影响,并找出哪个触点最重要。
缺点:低估了链中的第一个渠道;另外需要一定的编程技巧。
适用于将所有数据收集在单个系统中的企业。
3.BI/ML归因模型
这里开始,是本文最重点的内容——真不是为了完读率而这么写的
先解释一些两个名词
BI:商业智能,Business Intelligence,简称BI,指用现代数据仓库技术、线上分析处理技术、数据挖掘和数据展现技术进行数据分析以实现商业价值。
ML:机器学习,Machine Learning,简称ML,是亚瑟·塞缪尔(Arthur Samuel)在1959年用机器解决跳棋游戏的背景下提出的。该术语指的是一种计算机程序,通过学习而产生的一种行为,而这种行为不是由工程师明确的编程目的实现的。相反,它能够显示出工程师自己可能完全没有意识到的行为。这种行为学习机制基于三个因素:
计算机程序消耗的数据
量化(指的是目标或任务具体明确,可以清晰度量)当前行为和理想行为之间的误差或某种形式的距离的度量
使用量化误差指导程序在后续事件中产生更好行为的反馈机制
因此,BI/ML归因模型是通过BI工具和机器学习的结合,根据夏普利值/马尔可夫链分析逻辑从而评估我们的广告活动有效性,并且最大化洞察到每个触点的转化漏斗对客户促销的贡献。
夏普利值遵循的分配原则是“所得与自己的贡献相等”,因此不需考虑链中触点的顺序,而是评估触点的存在如何影响转换。
而马尔可夫链是一系列事件,其中每个后续事件都依赖于前一个事件。基于马尔可夫链的归因使用概率模型计算漏斗步骤之间的转换概率,让我们可以评估步骤对转化的相互影响,并找出哪些步骤最重要。
BI/ML归因模型设置转化漏斗的所有步骤并计算出概率,通过在马尔可夫链中呈现结果如下图:
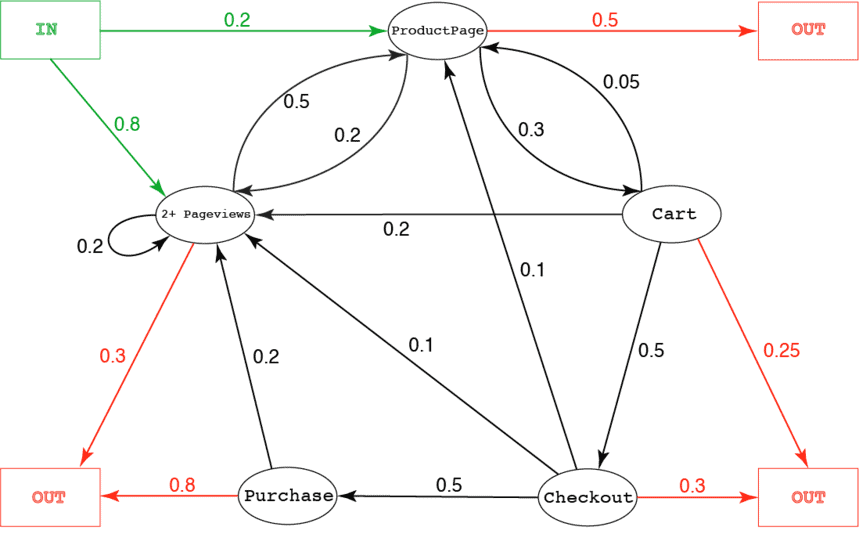
(图片来源:Jaron Tom)
大家可能会存在疑问:为何我们要做这么复杂的分析模型计算?

图片来源:Jaron Tom事实上,我们在数字化独立站演进Vol 1解读过,由于消费者购物决策路径因为数字化时代而不断拉长
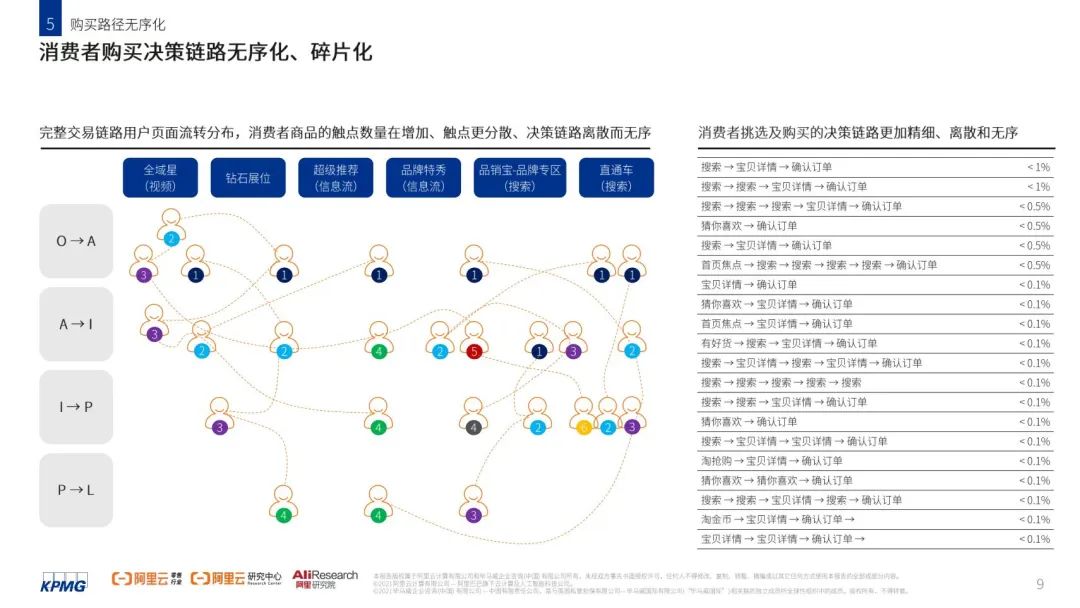
面向我们的消费者,可能在TikTok见到我们,Google搜索我们,最后可能依然还是Facebook下单。

(图片来源:Jaron Tom)但依然存在的问题是,在不同的广告服务和分析系统中使用着不同的归因模型
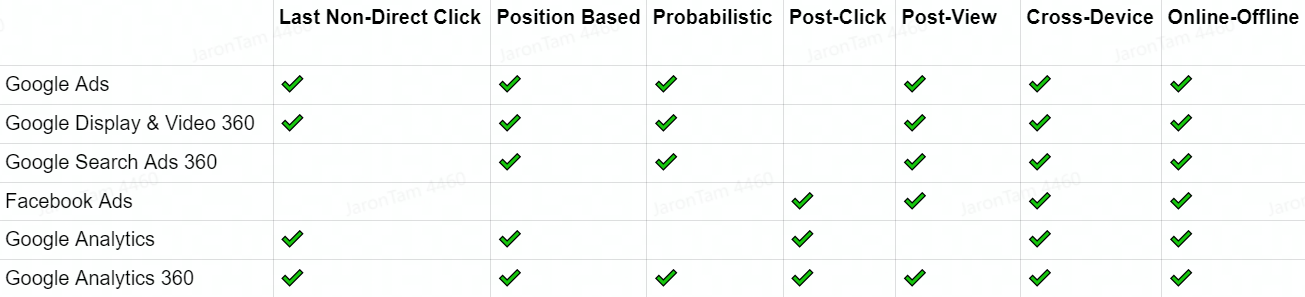
(图片来源:Jaron Tom)
大多数广告服务使用的是最后非直接点击模型(Last Non-Direct Click),后视图(Post-View)、动态追踪(Cross-Device)或其他模型
但这些模型无法跨服务进行比较:Facebook Ads以用户行为衡量广告价值,而Google Ads则采用品牌词的方法界定广告定价,哪怕我们全面启用以上工具(且不论成本问题)都无法打通完成数据闭环。

(图片来源:Jaron Tom)BI/ML归因模型的如何作用于我们的独立站?
1)洞察广告渠道运作效果
当我们的广告活动使用AIDA(A为Attention,即引起注意;I为Interest,即诱发兴趣;D为Desire,即刺激欲望;最后一个字母A为Action)模型,会分为认知、兴趣和转化三个阶段的时候,因此旨在影响广告下一阶段的活动可能在现阶段看起来无效。
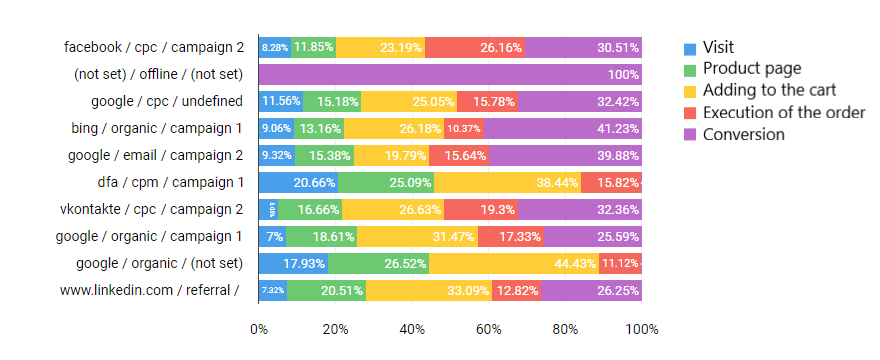
(图片来源:BI数据系统后台)
因此BI/ML归因模型对现有广告系列的ROAS真实评估,以及有没有完成AIDA整个过程,可以让我们不会错误配置广告预算。
2)比对不同用户群的获取渠道
计算每个会话的值,为不同的用户群组自定义归因模型
计算新用户和回访用户的ROI/ROAS,并比较不同群组的盈利能力
评估广告系列对向当前客户(“当前客户”群组)销售附加服务的贡献
评估首次购买者和下一次购买者,以找出哪些渠道更适合将新客户吸引到业务中
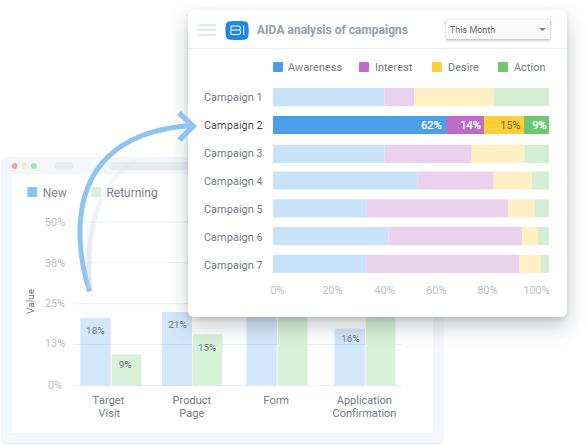
(图片来源:BI数据系统后台)
此外,通过了解会话的成本,我们可以计算在每个产品组上的花费和收入,评估针对不同地区、登陆页面、移动应用版本和应用程序的广告效果。
3)BI/Business Intelligence 商业智能
无需分析师的帮助或任何数据库/SQL知识即可基于归因数据构建报告,是BI/ML归因模型最大的优点。
计算归因模型后,通过BI工具根据添加的事件自动报告收入、转化次数、ROI、ROAS和CRR。
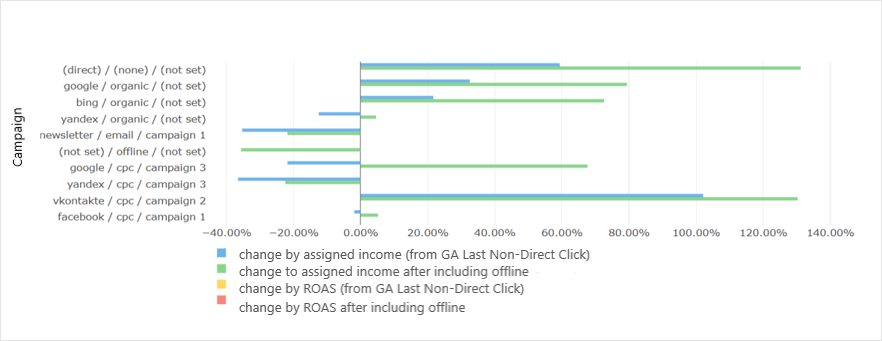
(图片来源:BI数据系统后台)
此外,使用方便的报告生成器创建个性化报告——更易于理解的图表和表格,更直观的展示
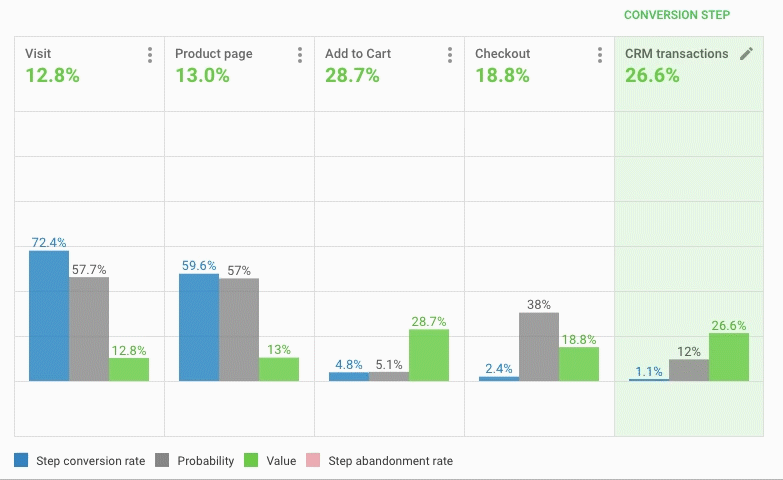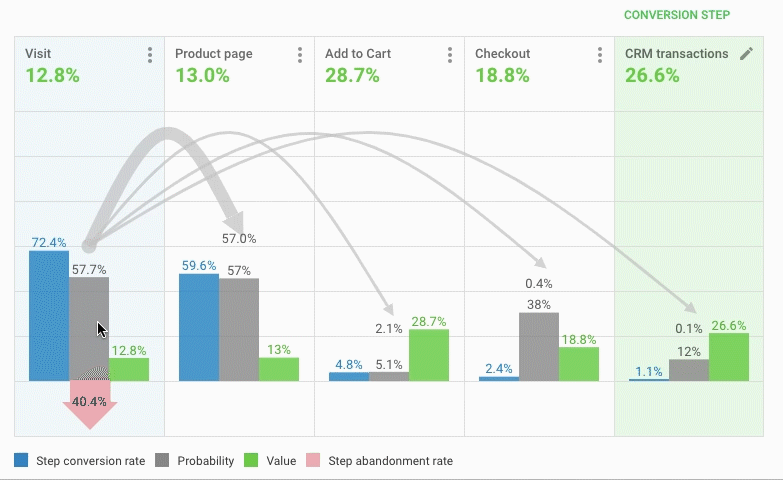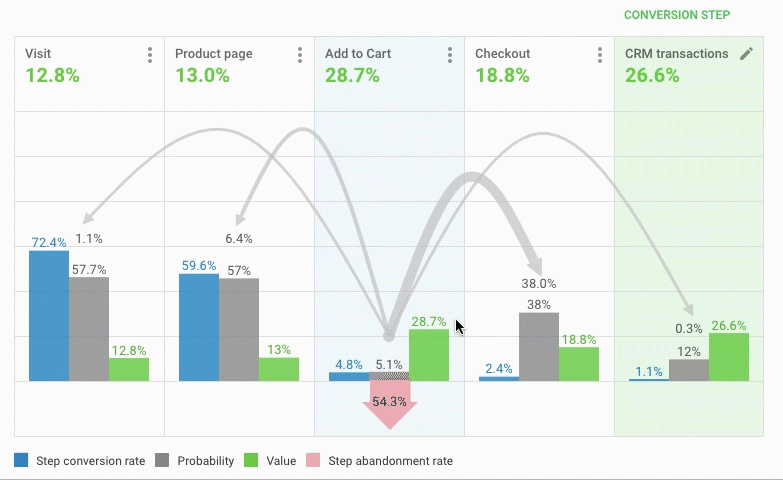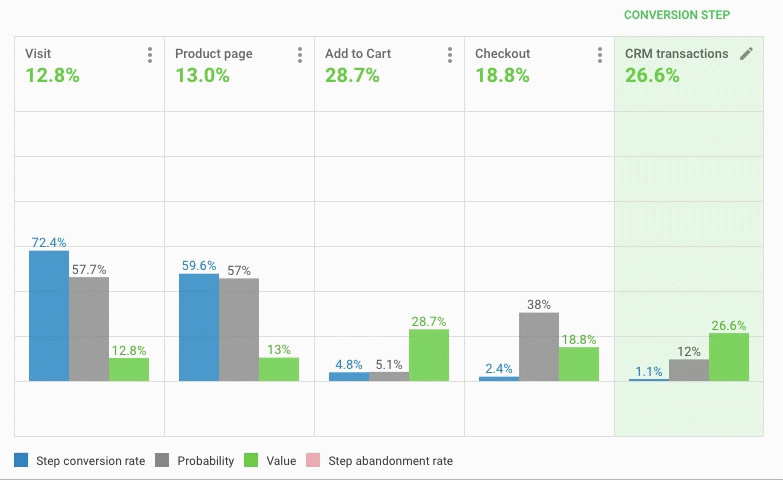
(图片来源:BI数据系统后台)
展示用户每个动作的广告真实ROSA(此处为BI面板操作录屏)
结语
在广告活动中:
吸引客户的成本会增加——广告服务将依靠更少的信息来将广告定位给合适的用户,而广告服务确定是否符合特定用户能力越低,其广告相关性就越低。这意味着点击率会降低,而每次转化费用会增加。
LAL相似受众和再营销活动的覆盖面将减少(假设这些类型的活动仍然存在)。事实上,重定向只会在第三方Cookie存在的时候起作用。在收到第三方Cookies后,如果用户访问其他网站,例如谷歌,那么第三方Cookies的寿命将会延长。这意味着重新定位(例如,在Google或任何其他有围墙的数字花园中)发生的时间可能比在假设的Criteo中重新定位的时间更长。由于Criteo通过其网站的覆盖率较低,因此无法访问用户级别的信息将不允许我们使用相似受众模式(LAL)归因。
Criteo是一家在纳斯达克上市(纳斯达克代码:CRTO)的全球性的效果营销科技公司,于2005年在法国巴黎成立。该公司核心业务是重定向广告(retargeting),其于2021年推出的内容投放方案FLEDGE,指根据近期消费行为将消费者匿名分组,然后通过AI查找出与特定组别最匹配的广告主的URL或者内容。
这一切都将导致小广告商离开市场,同时小卖家很难通过相关的转化来保证自己的利润。
在互联网时代,数据堪称土地、劳动、资本后的第四大生产要素,尽管我们独立站卖家常常忽略它,但其重要意义非同一般。更深一步,数字化能力比拼的并不是算法,而是数据,“得数据者得天下,得数据者得算法”。
(来源:JaronTam)
以上内容属作者个人观点,不代表雨果跨境立场!本文经原作者授权转载,转载需经原作者授权同意。
 收录于以下专栏
收录于以下专栏
































 闽公网安备35020602003453号
闽公网安备35020602003453号