







































































































 免费参与·100+跨境活动
免费参与·100+跨境活动 
 免费下载·4000+跨境资料
免费下载·4000+跨境资料 
 免费学习·2000+直播课程
免费学习·2000+直播课程 
 免费加入·15万+卖家交流群
免费加入·15万+卖家交流群 


2021-05-24 14:47

搜索引擎在对网页进行收录和排序时,首先需要搜索引擎爬虫来抓取网页。所以针对搜索引擎爬虫的优化,算是 SEO 的第一环。
去年在 AliExpress SEO 工作中遇到了一些搜索引擎爬虫的问题(主要是 Googlebot),比如爬虫抓取过量导致服务器崩溃、弹窗广告被搜索引擎判断为体验差、JavaScript 内容如何更好的抓取等。因此,我们启动了一个爬虫优化的专项 - “蜘蛛侠项目”,最后效果也不错:每天整体抓取量提升了几亿,流量提升了几十万,虚拟机也下线了几百多台。
中间有些方案是国内首创,甚至是国际首创,所以我还是比较开心的😄
搜索引擎爬虫的 SEO 优化,主要分为这几个部分:
抓取稳定性机制的建立 - 解决了服务器被搜索引擎爬虫抓崩的问题
搜索引擎爬虫的体验优化 - 解决了弹窗广告被爬虫判断为负面体验,流量影响的问题
SEO 差异化承接,包含人虫分离、缓存、SSR - 解决了 JavaScript 内容抓取的问题,也提升了整体抓取效率、降低了内部服务器成本
事情要从一次 P0 bug 说起。有一天我被叫去参加一个 P0 bug 的分析会:AliExpress 的搜索服务器崩了,用户无法正常站内搜索。后来发现 “罪魁祸首” 就是 Googlebot,抓取量突然提升了一倍,导致搜索服务器负载过高。开发同学也理解爬虫量的增加对 SEO 有帮助,但为了保证用户在站内正常搜索,只能把搜索引擎爬虫屏蔽了。
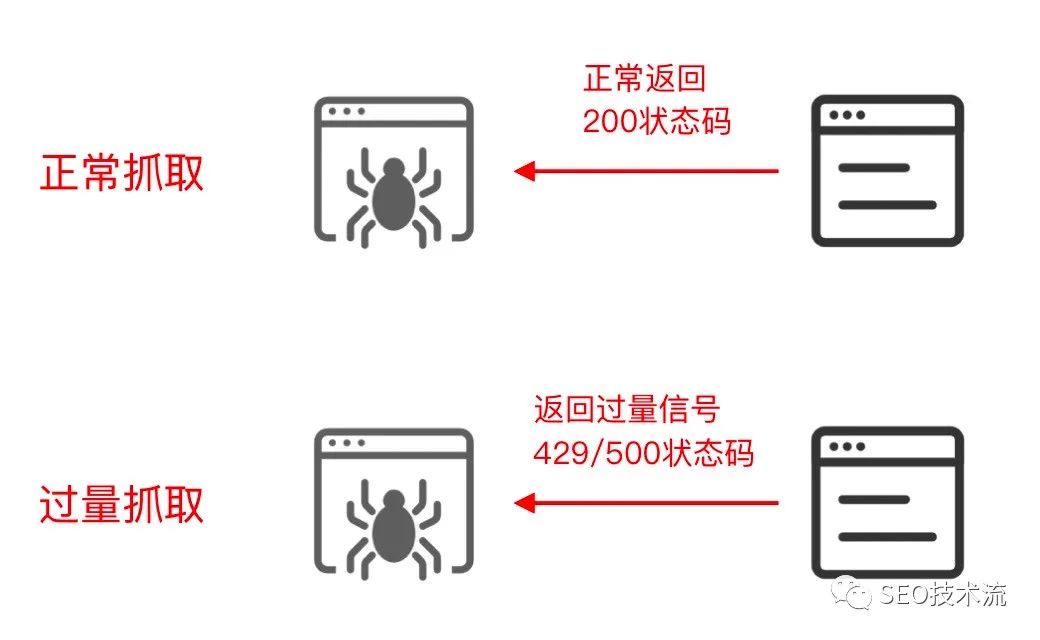
根据之前的经验,搜索引擎爬虫无法正常抓取时,会认为频道/网站无法正常访问(当时网站是返回验证码网页,还是200返回码),然后会大范围降低网站的排名和流量。于是,我马上提出了一版爬虫稳定性方案:当爬虫 QPS 超过一定“水位”时,返回对爬虫友好的状态码(429/500/503),告诉 Googlebot 目前是网站服务器压力过大,需要降低抓取频率;当爬虫访问在可接受范围内,就正常返回网页( 200 状态码)。当这个方案上线后,爬虫收到了信号,马上调低了抓取频率,服务器状态也迅速恢复正常。最后,我们将这套机制沉淀了下来,形成了一套长期可用的爬虫稳定性机制。
值得一提的是,双十一也成功应用了这个方案。大促期间为了保障用户的正常访问,就调低了爬虫的 QPS,把爬虫抓取限制在较低的范围。大促后,爬虫 QPS 设置恢复正常,SEO 流量完全正常,并没有出现往年大促抓取异常导致流量下降的情况。

在当前电商 SEO 领域,一般无线端的流量比例是高于 PC 端的,但难受的是这部分流量的转化远低于 PC(这中间可能有网络、设备、网站基建等原因)。AliExpress 为了提升无线端流量的利用效率,在用户访问时有个全屏遮罩的弹窗广告,引导用户下载 APP 再转化。但其实这类弹窗其实是非常伤害用户体验的,Google 在一个文档里也说过这类弹窗对用户体验的伤害,并且在排名上会有较大的影响(百度也有体验优化的文档提到广告的问题)。为了流量提升,我需要把这个弹窗下掉。第一期在不影响 APP 下降量的基础上,我针对 Googlebot 和其他搜索引擎爬虫下掉了这个弹窗。也就是说,当搜索引擎爬虫访问时,这个页面是不展示这个弹窗广告的;当用户访问时,弹窗广告还是正常显示。果然,下掉弹窗广告的第二周,SEO 流量就有了明显提升,最后粗估大概有 10 万+的流量提升吧。后续,在和其他团队一起推动下,用户侧的弹窗广告也下掉了,改成了对体验更友好,更智能的广告形式。这是后话了。
有一些用户可能会有疑问,如何区分搜索引擎呢?主要是通过访问时的 User-Agent 字段来判断。一般搜索引擎爬虫,都会有个固定的 User-Agent 的值。
以下是我整理的2个搜索引擎的特征字段:
| 搜索引擎 |
特征字段 | 官方文档 |
| Google |
Googlebo |
https://developers.google.com/search/docs/advanced/crawling/overview-google-crawlers?hl=en&visit_id=637570336155585559-1748790381&rd=1 |
| 百度 |
Baiduspide |
https://help.baidu.com/question?prod_id=99&class=476&id=2996 |
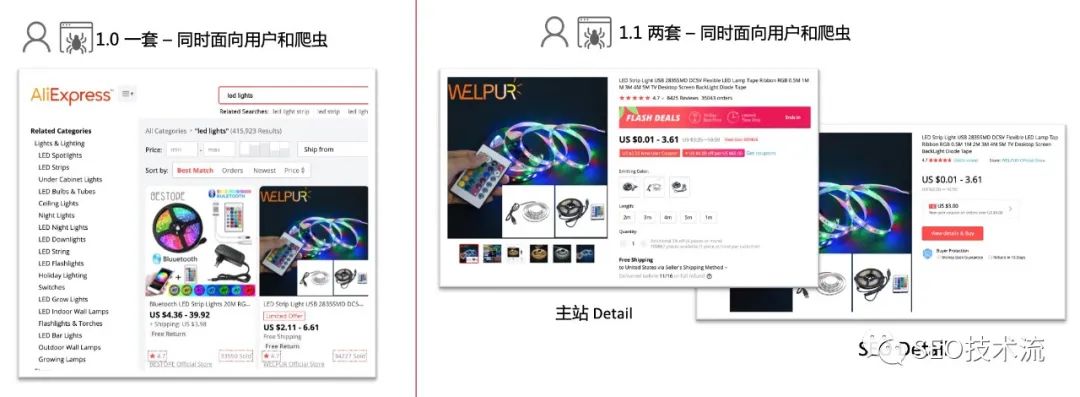
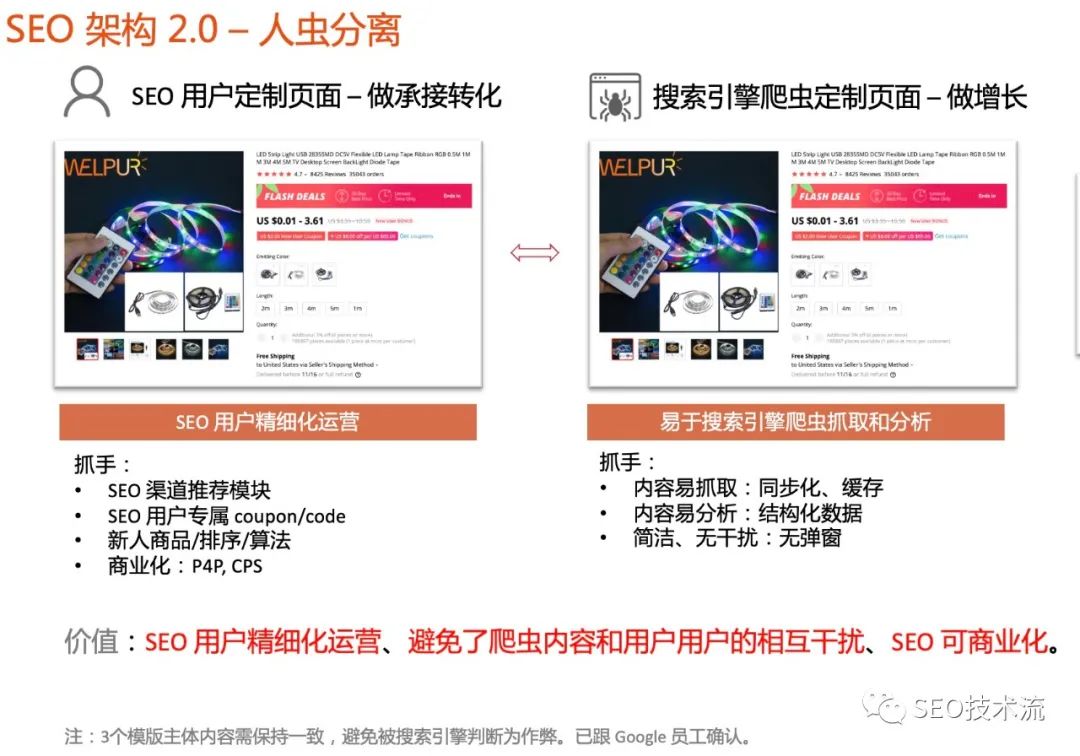
从弹窗开始,我意识到很多类似的场景:网站在针对用户浏览时,希望展示 coupon/code 来提升转化,也希望放上广告增加商业化收入,但在针对爬虫抓取时,希望网站越简单、越快越好。也就是说,其实同一套页面承载了两类用户的需求:真实的访问用户、搜索引擎爬虫。而且这两类的诉求并不完全一致的(如图架构1.0)。其实,AliExpress 也有个解决方案,就是做两套页面(2 个 URL),一套服务于真实用户的访问,一套是服务于搜索引擎爬虫的抓取(如图架构1.1)。但仍有个比较严重的问题,就是这两套页面都去做了 SEO 投放,内容高度重复,也就有了权重分散、排名内部打架的情况。所以我提出了新的方案,就是 SEO 差异化承接(如图架构2.0)。主要内容是:
同一个页面(1个 URL)根据真实用户、爬虫访问时返回不同的模版;
当真实用户访问时,展示 SEO 用户定制页面,主要考虑承接转化、商业化。比如放上新人的 coupon/code、P4P 广告等;
当搜索引擎爬虫访问时,展示爬虫定制页面,主要保证页面易抓取、易分析、良好体验,比如内容同步、页面缓存、结构化数据、代码精简、无弹窗等;
另外,两个页面的主体内容保持完全一致,避免被搜索引擎判断为作弊;
在实施侧,最好用同一个模版实现差异化,减少整体的开发成本。
这样既可以实现 SEO 用户的精细化运营、商业化,又能保证 SEO 流量正常增长。
最后,这个方案在开发同学的支持下逐渐实现,效果当然也很不错:
直接指标 - 整体抓取量提升了几亿,目前涨幅 50%+
间接指标 - 部分国家站的收录翻了一倍,流量也有 20~40% 的增长。
其实就是把真实访客和搜索引擎爬虫分开,具体的实现方式就是使用前文讲的 User-Agent 的方式来区分。分开之后,就可以有不同的策略:针对用户主要做承接转化、针对爬虫主要做易于爬虫的抓取和分析。
说实话,针对爬虫的缓存是最有效果的一部分。因为一方面,缓存能大大提升爬虫的抓取效率,另一方面,也能极大的降低服务器的成本。爬虫访问一个页面时,每次都需要实时调用服务器来获取一些数据(因为现在都是动态网页),所以有一些跟服务器的握手时间。另外,因为爬虫每天的抓取量巨大,对服务器也是一个不小的压力(参考第一部分服务器被抓挂的案例)。所以,我们把网页做了静态缓存放在服务器上,每次爬虫来抓取时直接返回这个静态缓存页面,无需动态获取数据。在提升抓取速度的同时,服务器的压力也得到了释放。当然,中间也有一些缓存策略,比如主动缓存和被动缓存、缓存频道的选择、缓存时间的选定等。
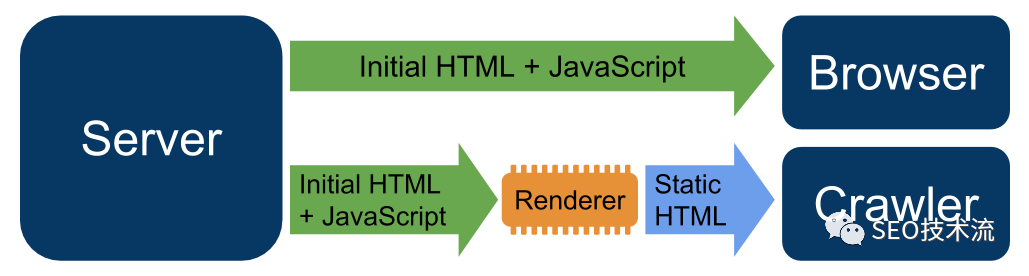
之前在《JavaScript SEO》提到过,Googlebot 已经具备了 JavaScript 内容的解析能力,但同步化仍是效率更高的方式,因为 JavaScript 渲染还是有一些成本。所以在人虫分离的架构下,就可以考虑采用 SSR+CSR 的实现方式:
针对爬虫,采用 SSR 的方式,方便爬虫直接获取到内容,不需要 JavaScript 引擎的渲染
针对用户,采用 CSR 的方式,更有利于用户体验,比如 LCP、CLS 等性能指标的优化
《减慢 Googlebot 的抓取速度》https://developers.google.com/search/docs/guides/reduce-crawl-rate?hl=zh_cn
《实现动态呈现》https://developers.google.com/search/docs/guides/dynamic-rendering
《JavaScript SEO 完全指南》https://www.zhidaow.com/post/javascript-seo-2021
(来源:)
以上内容属作者个人观点,不代表雨果跨境立场!本文经原作者授权转载,转载需经原作者授权同意。
(来源:SEO技术流)
































 闽公网安备35020602003453号
闽公网安备35020602003453号