











































































































 免费参与·100+跨境活动
免费参与·100+跨境活动 
 免费下载·4000+跨境资料
免费下载·4000+跨境资料 
 免费学习·2000+直播课程
免费学习·2000+直播课程 
 免费加入·15万+卖家交流群
免费加入·15万+卖家交流群 


2024-03-11 10:21
好消息是:本月没有核心算法更新。另一个不好不坏的消息:本期月报的内容依然很充实。谷歌自然是不会因为我们本月只有 18 个工作日而停止进取工作的步伐,何况今年的2月有29天,似乎是比去年同期还多一个努力的工作日呢!话不多说,本期的月报同样也会为你带来众多有关 Google 新动态、技术 SEO、AI 和 SEO、行业人士调研、经验分享、表情包等等资讯。
1.Core Web Vitals 指标变更:INP 将取代 FID
众所周知,Core Web Vitals 作为评估网页性能以及体现网站用户体验的一项技术 SEO 指标,自 2020 年上线以来一直都备受站长关注。
而在 2023 年 5 月,为便于更准确地衡量用户的互动情形,官方再次引入了 INP (Interaction to Next Paint, 下个绘制互动时间)指标,并预计在 2024年3月12日取代原有的 FID (First Input Delay, 首次输入延迟)指标。目前网站内各个页面的 FID 分数均能在 Google Search Console 报表中看到。
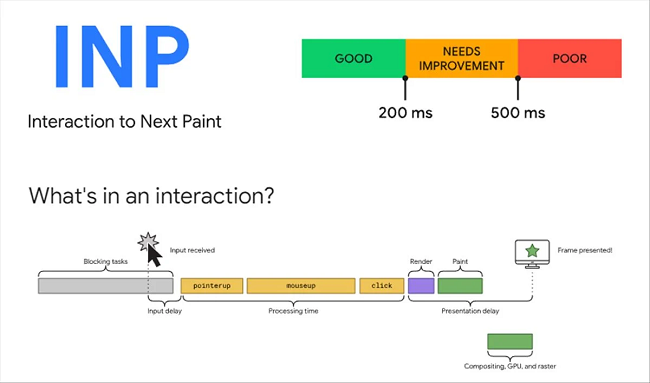
图片来源:https://www.searchenginejournal.com/
但该怎么理解 FID 这一指标?而谷歌为什么会替换呢?根据官方的定义,INP 用来观察网页加载之后,用户和网页的互动时间。用户在页面中一切的点击或按键输入行为都会计入为用户与网站的互动。而一连串行为中,最长的互动时间则为 INP 的数据。
与 FID 最大的不同在于,FID 指计算用户在网页首次的互动时间,因此 INP 的数据能够更客观地评估网页的互动是否存在过多的延误。从这里也能看出,INP 和 FID 其实都会统计前端 JavaScript 的响应时间。因此,有需要优化 INP 指标的伙伴,也可以参考 FID 的改善方式去优化这一指标。
信息源:https://www.seroundtable.com/inp-google-core-web-vitals-march12-36819.html
如果执行 INP 优化这项工作的过程中,还需要其它工具协作,也可以参考这篇文章噢!
https://www.searchenginejournal.com/inp-tools/507355/
2.Google:Core Web Vitals 并非直接的排名因素
新的一年我们依旧关心谷歌会不会推广新的排名因素。但可能在谷歌看来,推翻你的认知会更容易一些。
近日(2月5日),谷歌联络处的代表 Danny Sullivan 在 X 上回应网友的提问时,表示:谷歌在决定网页排名时会考虑很多因素,而不仅仅是页面体验或核心网络指标这类因素。他强调即便是这些因素,也不一定直接影响网页的排名。换句话说,谷歌的排名算法非常复杂,不会只依赖某个单一的指标。
到底 Core Web Vitals 是不是确切的、谷歌纳入衡量的排名因素呢?这个话题 Search Engine Journal 其实在去年 12 月的时候,有发布一篇文章:Are Core Web Vitals A Ranking Factor? 整合谷歌官方人员的观点,探讨过。甚至在搜索 Core Web Vitals 是否为排名因素这一问题时,能够看到行业知名人士 Backlinco 的文章里会把其当成是排名因素。

图片来源:https://www.searchenginejournal.com/
能确定的是,这个指标在谷歌大力推广 Helpful Content 的过程中,能够更直观地帮助评估页面的浏览体验够不够用户友好。虽然在看完一系列的整合后会感受到谷歌依然会比较谜语人,但正如官方文档的定义或者说 Danny 的解释,CWV 不是唯一因素,SEO 的工作始终要关注整体效应。
信息源:
https://www.seroundtable.com/google-core-web-vitals-search-ranking-factor-36834.html
3.浓缩再浓缩!新版 《谷歌 SEO 入门指南》 发布了
2月2日,新版《谷歌 SEO 入门指南》如期而至。本次更新的版本删减了比较多的内容,变得更加简洁易读,即便是对SEO一无所知的人也能快速获取关键信息。而对于已经有一定基础的SEO专业人士来说,这份指南可能内容过于基础,但对于初学者来说,它提供了一个很好的起点,帮助他们了解SEO的基础知识和重要概念。
除了2008年的首版外,实际上谷歌对这份SEO入门指南进行了几次更新,分别在2010年和2017年,目前的改动主要集中在:
删减了这些内容:
SEO 术语:相关术语会直接透过语境便于读者理解
结构化数据:这部分内容谷歌认为属于进阶的话题
移动端友好:因为目前大部分新站点都会注重移动端的优化
分析站点性能:属于 SEO 比较后期的工作,不太符合目前初学指南的定位
新增了这些内容:
为什么这样做:用于帮助读者更好地理解SEO的重要性和实施的动机
关于重复内容:添加了关于什么是重复内容以及如何解决重复内容问题的解释,并新增了一个小节简要介绍视频内容的 SEO 优化
SEO 理论和想法:新增了关于常见SEO理论和想法的部分,指出了人们不应该过分关注的领域。同时,也新增了有关看到SEO效果可能需要多长时间的讨论
精简压缩了这些内容:
图片内容:特别强调alt文本的重要性
链接部分:强调了链接对用户和搜索引擎的作用
网站结构部分:删除了如导航部分,404错误页面的处理,以及面包屑设置的具体内容,因为这些内容更偏向于进阶主题
能看出来,此次改动对刚开始接触SEO的人来说,整份文档在降低了阅读难度的同时,保留了对 SEO 至关重要的信息和建议。
信息源:
https://www.seroundtable.com/google-revised-seo-starter-guide-36831.html
4.网站的 404 死链还没有彻底清除,直接在 GSC 上点击验证修复会有问题吗?
处理站点的 404 错误是 SEOer 的日常工作事项。但对新手来说,404 错误代码似乎又是一个容易让人迷惑的概念。于是谷歌的 John Mueller 在本月也回应了网友处理 404 错误的问题。
404状态代码表示请求的网页不存在,这可能是由于网页已删除或URL地址错误导致的。而不是指Google在页面上发现了需要修复的错误。在GSC中,验证修复404错误的过程是为了跟踪和管理网站上的丢失页面。
理论上,如果已知一个404状态是永久性的且页面永远不会返回,那么更正确的响应应该是显示410状态码。但Google几乎将404和410响应码等同对待,410响应会使页面从Google的搜索索引中稍微快一点被移除,但最终结果是相同的。
针对站点内部或外部链接失效导致的 404 错误,John Mueller 给出了以下建议:
如果是内部404错误:提交验证修复可以帮助您跟踪和管理网站上的丢失页面,并告诉Google哪些页面已经被修复。
如果是外部404错误,通常不需要追求修复,除非链接来自于合法的网站并且对用户体验产生了负面影响。
有的 SEO 专家也会建议使用 301 重定向操作,将错误的 URL 导流到正确的 URL 来修复入站链接。总的来说,“验证修复”功能的目的是帮助站长跟踪修复的效果,以确保Google也看到了这些更改。而处理外部链接导致的404错误时,需要权衡修复这些链接的投入产出比。
信息源:
https://www.searchenginejournal.com/google-on-404-errors-and-search-console-validation-fix/508310/
5.提交 Sitemap 需要注意这一点,避免 Google 无法正常爬取
如果你的 XML 站点地图文件的命名中有带连字符,并且连字符后紧跟2个以上的数字时,可能会触发 GSC 的“无法获取”错误。这个 bug 是由 Screaming Frog 的团队首次发现并发布到 X 上的。
举个例子:
如果你的站点地图文件名是 /sitemap-10.xml,它会触发“无法获取”错误。
但使用 /sitemap10.xml 作为文件名时,即便是同一个文件,就不会触发任何错误。
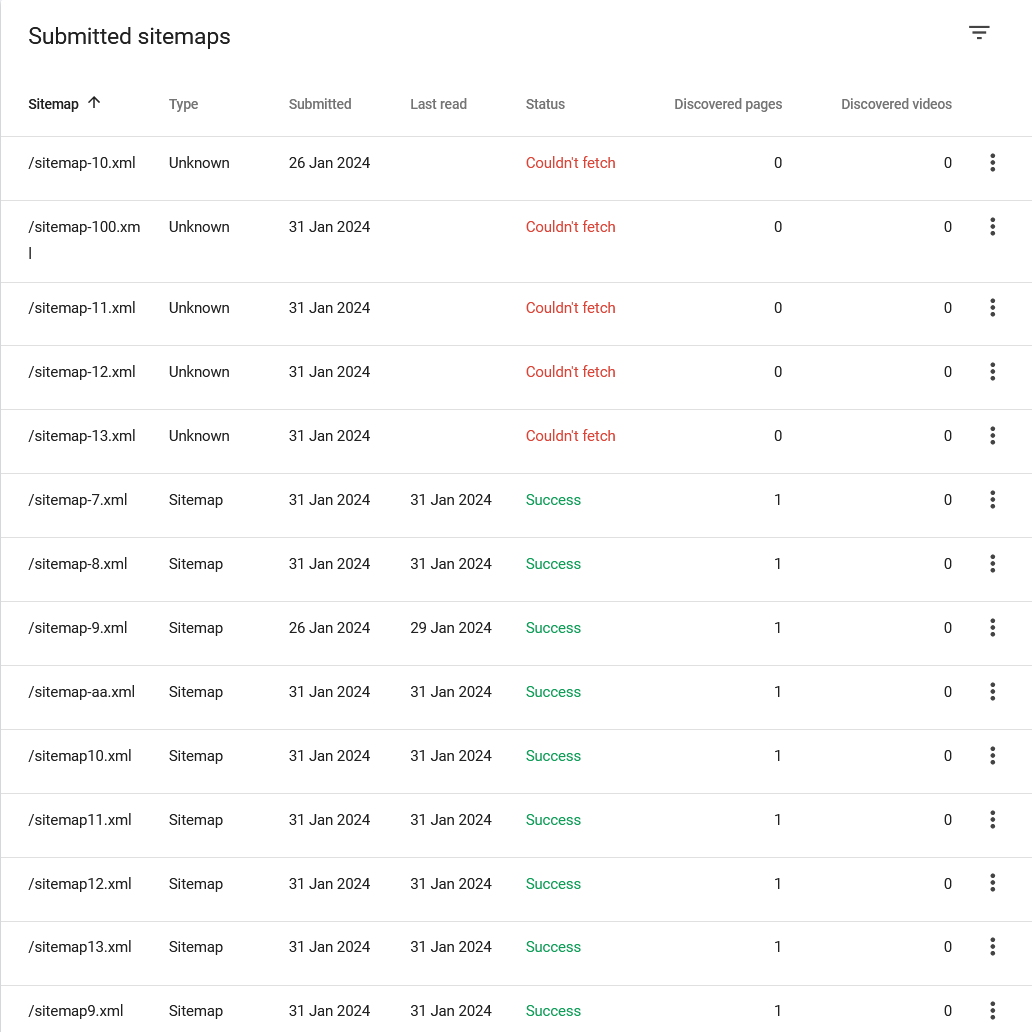
Screaming Frog 也在多个站点中测试提交站点地图,但还是得到同样的结果,谷歌对此问题尚未作出回应。
信息源:
https://www.seroundtable.com/google-sitemaps-error-with-hyphenated-file-names-36829.html
6.要如何应对 Reddit 更频繁地出现在 SERP ,抢占排名呢?
本月备受瞩目的信息除了 Sora 之外,还有谷歌与 Reddit 达成了人工智能培训协议,以便于训练和增强自家的 AI 模型。但就算谷歌还没和 Reddit 正式达成合作,不少网站运营人员可能也观察到 Reddit 甚至各种大型的平台在 Google 的排名优势越发突出,可能会对不少小型独立站点的可见性构成挑战,排名空间遭到挤压。
本月,主营业务为家居空气净化器的独立站 HouseFresh 发布了文章:Google is killing independent sites,而让事情得以发酵,获得大家、甚至谷歌官方关注的契机在于,同样的页面标题,在内容原创的情况下,搜索结果页中 Reddit 帖子的排名直接超越了这个独立站。而尽管 Reddit 的帖子也有链接到原文章,但就结果来看,可谓是无济于事。这一现象引发了关于大型网站与小型网站在搜索排名上的竞争不平等的讨论。
而援引消息的 Search Engine Land 在本月也有发布另一篇文章,通过摆数据的方式分析 Reddit 在 Google SERP 上是否存在过度展示,导致搜索结果多样性削弱的问题。文章的分析作者 Glen Allsopp 通过分析10,000个关键词短语,发现 Discussions and forums 的搜索样式出现了77%的时间,其中 Reddit 几乎占据了Google讨论和论坛SERP功能预留位置的三分之二。这一观察也引起了 Reddit 的注意,他们回应:分析报告存在缺陷且具有误导性,并强调展示的 Reddit 帖子并非全都包含网盟的 affiliate 链接。
总的来说,尽管大型网站和小型独立网站之间的竞争不平衡的现象确实存在,但小型独立站点依然可通过专注于创造高质量的原创内容、建立自己的社区鼓励用户参与,和灵活调整SEO策略找寻不被大型平台主导的关键词(也就是避开:用户会自发在末尾加 reddit 的关键词),最终仍有机会在搜索引擎中取得好的排名和可见性。
信息源:
https://searchengineland.com/reddit-dominates-google-search-discussions-forums-437501
https://searchengineland.com/article-complaining-about-being-outranked-on-google-being-outranked-by-reddit-437736
https://www.seroundtable.com/google-reddit-content-deal-36944.html
7.不想让站点内容被用于 Google 的 AI 训练?更改 Google-Extended 网络爬虫文档就能实现!
本月9号,Google 更新了其 Google-Extended 网络爬虫用户代理文档。主要更新了相关的 AI 产品命名,并列明了爬取对搜索的影响。另外,不想让站点内容参与 AI 训练的用户,现在有了更多的控制权,可以决定自己的网站内容是否被用于 Google 的AI训练,而且这一选择不会影响其在 Google 搜索结果中的表现或排名。这为站长提供了更大的灵活性,同时也要求站长需要对如何管理自己的内容和其在AI技术中的应用有更深入的了解。
信息源:
https://www.searchenginejournal.com/google-clarifies-the-google-extended-crawler-documentation/507645/
8.算法更新蓄力中:2月7号-8号流量波动明显
距离上一次未经证实的算法更新(1月23日-24日)不到两周,本月主流的 SEO 检测工具再次观察到排名情况有剧烈波动。据 SearchRoundTable 的社区论坛讨论,有的网站流量在这期间正常增长,也有的则经历了流量或关键词排名下滑。如果在这段时间内,有站长发现了不寻常的流量波动,很可能也是算法导致的,建议及时调整自己的 SEO 策略噢。
信息源:
https://www.seroundtable.com/google-algorithm-update-36862.html
9.新的 SERP 样式:提供购物功能相关的菜单
Google正在测试一个专门针对搜索结果中购物功能的菜单。这个新菜单将添加并应用到购物相关的搜索结果中。用户在点击菜单按钮周,会展示以下子区域的链接:购物首页、订单、购物设置和购物帮助。这一变化能够让用户的购物体验更加集中和便捷。
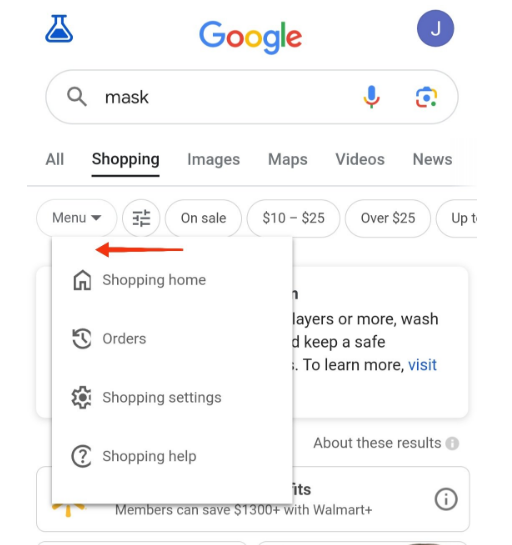
同样,这也意味着Google搜索正变得更加偏向于电子商务和购物。从事电商相关的独立站运营人员,可以尝试:
优化产品页面和购物相关内容,确保它们符合 Google 的搜索和购物功能标准。
了解 Google 购物特性的新变化,利用这些特性提高产品在 Google 搜索结果中的可见性。
考虑在内容策略中加入更多与购物相关的元素,比如详细的产品描述、用户评价以及优惠信息,以吸引 Google购 物搜索的用户。
信息源:
https://www.seroundtable.com/google-search-testing-shopping-menu-36820.html
10.Canonical 链接属性相关文档更新,及时检查保证站点链接符合规范
本月要关注的 SEO 技术规范还包括了 canonical 注释。2月15日,Google 更新了其规范链接(canonical link)文档中关于使用rel=canonical链接注释的部分,明确指出带有特定属性的rel=canonical注释不会视为标准化的网站链接。
各位站长看到这则信息之后也无需迷茫,这一更新意味着需要检查和更新网站中的规范链接注释,确保它们按照Google的最新指导方针进行配置。具体建议如下:
核对现有的规范链接注释:确保不要在用于规范化目的的rel="canonical"链接上错误地使用hreflang、lang、media和type属性。
正确使用备选版本链接:对于指定页面的语言和国家备选版本,确保使用link rel="alternate" hreflang注释,而非错误地将这些属性与rel="canonical"混用。
遵循RFC 6596标准:Google支持按照RFC 6596标准描述的rel canonical链接注释,因此确保你的规范链接实施遵循这一标准。
通过遵循这些规范,及时与技术人员沟通,调整站点可能存在问题,帮助确保网站在Google搜索中的表现更加准确和有效。
信息源:
https://developers.google.com/search/docs/crawling-indexing/consolidate-duplicate-urls#use-rel=canonical-link-annotations
11.电商结构化数据样式更新:相似的产品变体可以标记属性了
Google 最近宣布支持产品变体结构化数据,通过新增的三个属性:hasVariant、variesBy和productGroupID,来处理电商网站列出产品变体(类似同款不同色的产品)的大部分方式,意在让搜索结果展示效果更直观准确,改善用户体验。
而运营电商独立站的站长则需要更新网站上的结构化数据,以确保产品变体正确地被Google识别和索引。具体的操作建议可以在信息源的链接中查阅。
信息源:
https://www.seroundtable.com/google-product-variant-structured-data-36924.html
12.需注意:AI 生成的图像需保留图像元数据
Google 为商家中心(Google Merchant Center)使用AI生成的图像发布了新政策。简而言之,你需要确保这些图像的元数据标记为使用AI生成,避免潜在的问题或处罚。
Google 要求在商家中心使用AI生成的图像时,保留指示图像是使用生成性AI创建的任何元数据标签。为此,官方文档还特别提到:不要移除诸如 trainedAlgorithmicMedia 这样的嵌入式元数据标签。所有AI生成的图像必须包含 IPTC DigitalSourceType trainedAlgorithmicMedia 标签。谷歌还提供了关于IPTC照片元数据的更多学习资源。
此外,对于计划在文章头部或其他位置使用AI生成的图像的内容运营人员来说,尽管谷歌目前尚未为文章和AI图像制定标准程序,但你可能也可以考虑给这些图像标上某种标签,表明它们是由AI生成的。这样做不仅有助于透明度,也可能对未来可能出台的相关标准做好准备。
信息源:
https://www.seroundtable.com/google-merchant-center-requires-labels-ai-images-36922.html
13.John Mueller 发话:滥用收录 Indexing API 的网站有被认为垃圾站点的嫌疑
Google 提醒网站管理员,滥用 Google Indexing API 这一行径通常容易让站点与垃圾站或低质量网站挂钩。John Mueller 强调,Google Indexing API 应仅用于工作职位发布和实时直播内容,对于其他用途,Google 官方不支持且表示这种做法不会有效。
尽管有人尝试将其用于其他目的,并称其可以快速索引内容,但这些内容通常会在短时间内从索引中消失。Mueller 表示,虽然看到有人热衷于尝试使用该 API 做更多事情是件好事,但大多数这类尝试都是为了 spam 或上线大量的低质量内容,因此这种做法是不被支持的,还可能影响网站的信誉。
信息源:
https://www.seroundtable.com/google-indexing-api-abuse-spammy-low-quality-36919.html
14.Google:AI 有帮我们更好地鉴别虚假的评论内容
Google 在2月13日发布博文表示,利用 AI 技术,Google 的算法现在可以更有效地识别可疑、虚假的线上评论,例如:能够检测在不同商家页面上复制的相同评论,或评分的异常波动。这一进展对于保护 Google Maps 和 Google 搜索上的本地商家免受可能破坏其声誉的欺诈性评论至关重要。数据表明,Google 在2023年阻止了超过1.7亿条假评论。这一进步标志着与前一年相比,准确性提高了45%。
因此,站长在维护网站的评论内容时,建议落实这些措施来维护网站的声誉:
专注于真实性:鼓励真实的客户反馈,避免使用人为手段提高评分。
监控和参与:定期检查商家评论,寻找任何可疑活动,并通过回应正面和负面评论积极与用户互动。
信息源:
https://www.searchenginejournal.com/google-uses-ai-to-detect-fake-online-reviews-faster/508093/
1.多语种站点运营:挑战和应对方式
SEO 这一行,有一个常见的情况,站长即便不是精通某个小语种的专家,项目的站点却有多语言、跨地区运营的需求。本期推荐阅读的干货是来自 Search Engine Journal 的霓虹地区编辑 Motoko Hunt 在本月发表的文章,过往她也针对 Local SEO 领域,在网站上发布过不少有洞见力的文章。
从文章中,你会了解到:管理多语言和多国家网站的SEO面临独特挑战,包括处理重复内容、不同国家站点的搜索结果显示问题、以及各个市场之间的SEO流程、技能和重点区域的差异。而文章将会围绕她在团队管理和协调、代理商合作事项上的情形,去解决并克服沟通障碍(如语言和时区差异)、人员之间不同的SEO技能和知识水平、项目之间不同的预算分配、以及在内部团队和代理商之间存在的不同SEO结构相关的问题。
原文:
https://www.searchenginejournal.com/unique-challenges-multilingual-multinational-websites/503481/
2.大品牌是否真的在 Google 中更有优势?这种形势会发生变化吗?Google 会干预吗?
在近期的资讯中,不乏报导 Reddit 挤掉独立站排名的现象,也引起了业界不少的议论。SEO 的专家 Marie Haynes 也在最近发布了文章,探讨了大品牌在谷歌搜索结果中的主导地位以及未来这一现象可能发生变化的原因,给大家打打鸡血,加油鼓劲。
她提出,尽管大品牌因为链接(可能也可以理解为链接攒下的权重)而占据优势,但谷歌对有用内容的奖励机制正在变化。谷歌的AI系统,尤其是最新的Gemini 1.5模型,正在提高识别和奖励真正有帮助内容的能力。这意味着,即使是小型网站,只要内容真正有用、独特且展示了真实经验,也有机会获得更好的排名。
原文:
https://www.mariehaynes.com/why-big-brands-dominate-google-and-how-this-is-soon-likely-to-change/
3.全世界的内容都一样烂时,谷歌会给用户展示什么样的结果?
接触 SEO 久了之后,你是否偶尔会质疑:其实谷歌压根都分辨不出内容质量的优劣,网站之间的排名竞争不过是玄学呢?
如果你会因为谷歌算法、排名机制对站点带来的负面影响,而感到迷茫、愤世嫉俗时,不妨阅读这篇文章,换换心情。文章探讨了为什么一些网站的内容没有在谷歌搜索中获得好的排名,可能的原因是这些内容质量其实并不高。作者Danny Goodwin 指出,很多人认为他们创造的内容是高质量的,但实际上这些内容在最好的情况下也只能算是次优的。
他提出,真正优秀的内容是非常罕见的,不论是AI生成的还是人类创造的,网络上充斥着大量的普通内容。此外,文章也同样提及了大品牌在搜索结果中的主导地位,以及谷歌如何处理这个问题。
最后,别忘记,SEO是一个长期的游戏,需要不断地学习和调整策略,同样地,建立品牌声誉是一个长期的过程,需要耐心和持续的努力。
原文:
https://searchengineland.com/google-rank-search-content-sucks-437752
4.有什么方法能让 AI 内容变得更像人写的
不可否认,像 ChatGPT 这一类型的生成式 AI 大大解放了内容的生产效率,但生成式 AI 同样也衍生了很多与内容质量有关的问题,包括内容准确性不佳以及内容重复这些常见现象。
所幸,随着我们对 AI 指令的理解加深,是有办法通过提供更详细的提示词指令来精细化 AI 生成的内容的。 这里推荐的文章提供了如何使用 ChatGPT 来创造听起来更像人类的长篇内容的策略。作者强调了给AI设置详细的提示以产生更具吸引力、更富有情感和针对特定受众的文章的重要性。这包括明确内容的主题、想要的情感和语调、目标受众、具体细节、例子和类比,甚至是期望的字数范围。当然啦,最后的内容还是要人工复查,必要时也可以增加人性化的创意元素,保证最终的成稿能够做到既有深度,又能引起共鸣。
原文:
https://searchengineland.com/how-to-make-your-ai-generated-content-sound-more-human-437854
5.为什么不建议你阻止 GPT 的 bots 爬取网站内容
有的站长可能会担心自己站点的内容被用于 AI 训练之后,会产生负面影响。除了 Google 官方提供的如何不让内容被用于 AI 训练相关教程外,不妨看看另一个视角,AI 爬取网站内容,有哪些好处呢?
这篇文章讨论了为什么不应该阻止 GPTBot 抓取你的网站,并提出了三个主要的理由。
首先,每周有1亿人使用 ChatGPT,不允许 GPTBot 抓取你的网站意味着错过了最大化品牌可见性的机会。
其次,随着 AI 在营销领域的变革,生成式引擎优化 (GEO) 正成为 SEO 的一个子领域,不参与其中将导致错过重要的市场机会。
最后,OpenAI 承诺最小化伤害,并在其平台上明确表示将尽量减少伤害,有政策尊重版权和知识产权,GPTBot 也会过滤掉违反其政策的来源。
或许,也可以抱着做慈善的心态,让 AI 的训练数据源能够保持一定质量,为提高 AI 信息的准确性贡献力量?
原文:
https://searchengineland.com/why-not-block-gptbot-crawling-your-site-437902
以上就是我们本期Google SEO月报的全部内容, 希望大家喜欢! 如果对本期内容有疑问, 可以在评论区留言告诉我们。
(来源:Kenyth)
以上内容属作者个人观点,不代表雨果跨境立场!本文经原作者授权转载,转载需经原作者授权同意。
 收录于以下专栏
收录于以下专栏

































 闽公网安备35020602003453号
闽公网安备35020602003453号